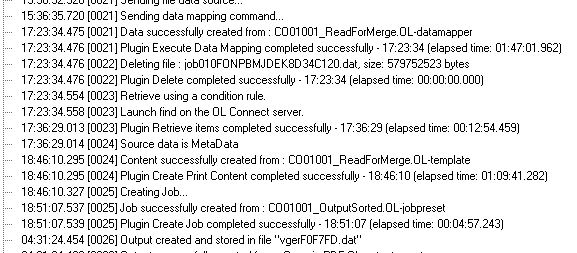
I have a job coming in that is 800k pages in total that is made up of several document types which need merging based on address, I’ve been able to chunk it down slightly so it’s not 800k in one hit. However I’ve just run the 1st chunk of 250k pages and it’s taken 13 hours to run the job. There is still another stage after this that needs doing as this stage sorted the data by address and the next stage will then split the documents up based on address and add production marks etc.
Looking at the logs it took 8 hours to do the actual output stage
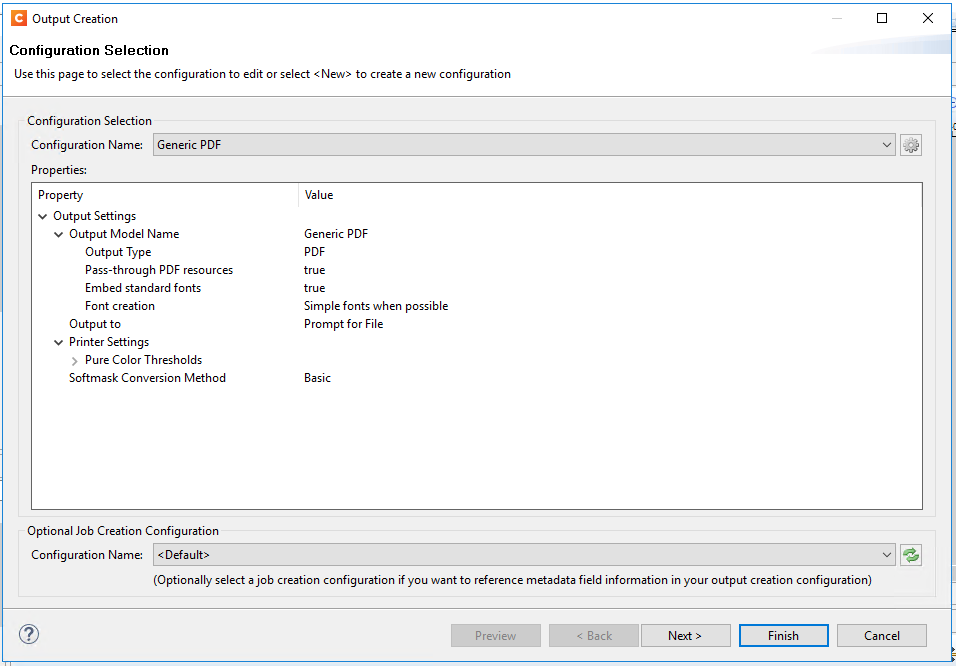
This is obviously a very big worry as in total this is going to take days to process by the looks of it and we don’t have days to process everything as there is a large amount of days worth of printing and enclosing. Below is a screen shot of the output settings we are using, can anyone suggest anything that may speed up the processing.
Just as a FYI also, this is raw data that comes in so all PDF’s have been created by PReS. The steps it goes through is:
Run several data files through relevant document type mapper to create PDF’s and split into relevant output files
Run PDF’s from different document types in batches where possible through mapper etc and sort output by address
Run sorted PDF’s back through and split based on address changing and add production marks etc
I’ve already split each of the above steps into different processes as we have been getting IPC connection errors so I don’t want to loose days worth of processing if it does fall over and we have to start from the beginning again.
Looking at the first screenshot, we’re missing a bit of info. You mention it takes 13 hours to run the job, 8 of which are spent just in the Output module (whose log results we can’t see in the screenshot). But the other tasks we see (DataMapping, Retrieve Items, Create Content, Create Job) take about 3h15 together. 8+3 = 11, so from what you’re saying there are additional steps that take an additional 2 hours. It would be interesting to know what those steps are.
But let’s focus on what we do know. Almost 2 hours to run the DataMapper on 250K records seems excessive. You mention “raw data” … what format is that exactly, and can you tell us how complex the data mapping config is?
Given that the Content Creation task (which is usually the slowest of all tasks) is almost twice as fast as the DataMapper, it looks like the composition step is relatively simple. From the little info we have here, it looks like you’re extracting a lot of data… that you are not really using in the Content Creation phase.
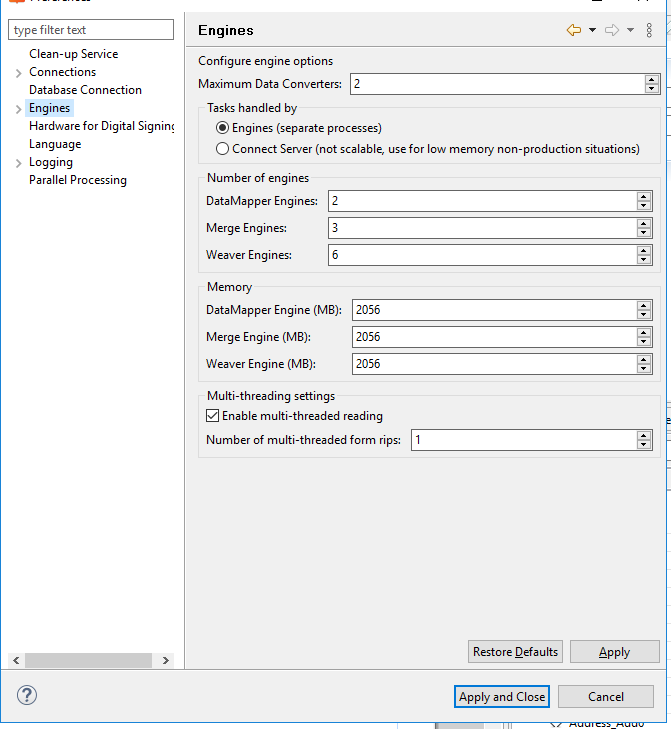
That said, can you tell us what your parallel processing settings look like in the Server Configuration tool? And also, what kind of hardware (RAM, CPU) this is running on?
Sorry I made not have made it clear, the above timings is for item number 2 in the above list. For this stage it’s taking a several PDF files in as the input data.(which have been created by PReS in stage 1). It’s reading in these PDF’s and in the mapper is extracting the name and address. The job config file is then sorting the documents by the name and address and outputting as a single file so we can then read this output back into another mapper and template which then splits the PDF into documents when the address changes.
This is running on a VM with 32gb of RAM and 8 virtual CPU’s. Below is a screenshot of the server configuration