I have a data file with 100k records. I have a condition in my datamapper to “stop processing record” above record.index: 10k. I have the feeling the datammapper is also running through all the records above 10k to see if they are above “record.index: 10k”.
A data file with 10K records is done way before the data file with 100K, but they produce an equal number of records.
Is there a way to stop datamapping as soon a I hit 10K and really ignore the rest?
Oh Wow, I did not know this since I use this method to generate proof files which are generally 50 records. So for the mapper to still process the full file is a bit silly. Glad someone noticed and brought it to OL’s attention.
The feature is called “Stop processing record”, not “Stop processing data”. So it makes perfect sense, in that context, that Workflow would keep processing the rest of the file.
But as I stated, I think @Filemon’s suggestion makes sense so we could also add that option.
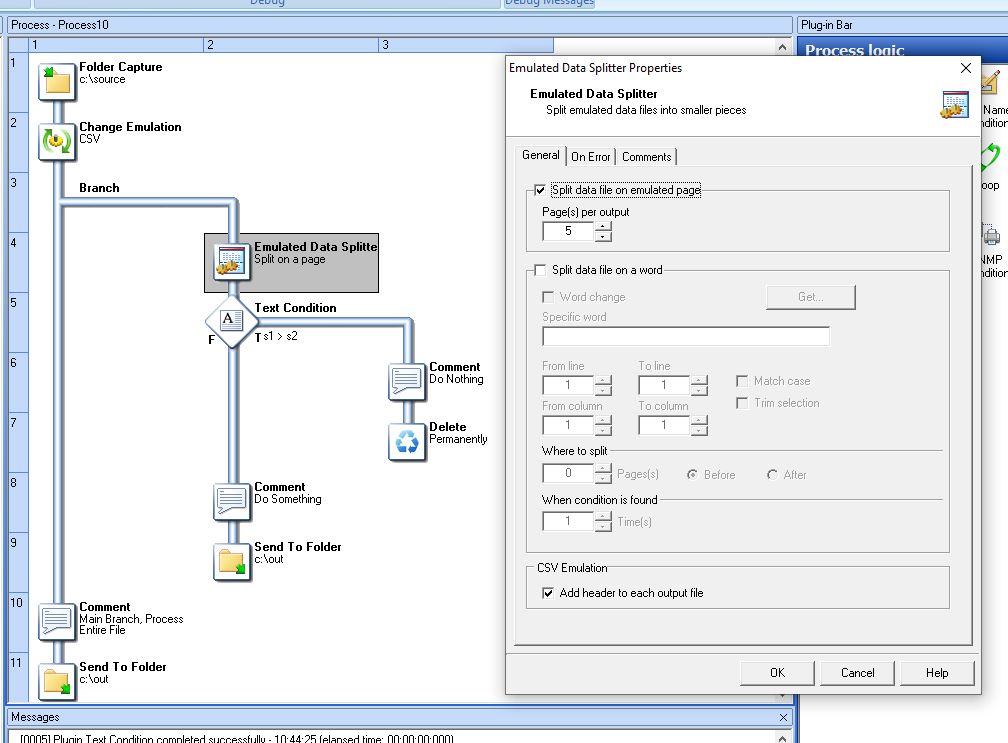
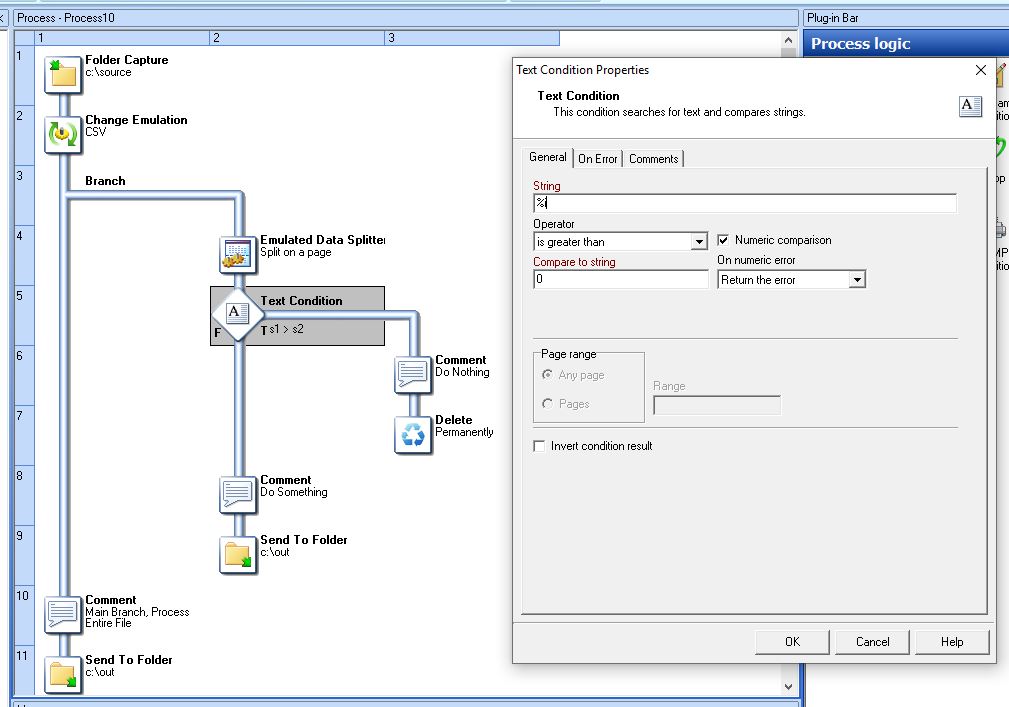
Then to ensure that only the first 10k are treated, you use a simple text condition which checks which loop we’re on using the %i system variabl. If it’s anything other than 0 we know that we are not on the first chunk of data and we skip over it.
So you’d put your datamapper and the rest of the Connect plugins you’re after in the Do Something branch. Back in the main branch, if you wanted to process the entire record set, you could do so as well. Or not. Depends on what you’re wanting to do.
%i isn’t going to be much use, I would think. It’s just giving you the current iteration of the loop, but you haven’t got a built in way of knowing how many loops it’ll do there.
A very simple way that you could get the file from the last loop would be to output the split file to a temp folder at each iteration. Give it a static name on output so that each loop overwrites the previous file. After the loop, another branch downstream would be able to pick up that file and process it seperately.
This doesn’t seem terribly efficient to me though unless you’re still processing all of the split files as well.
The File Store - Delete File plugin would be used in conjunction with the File Store - Download File and File Store - Upload File plugins.
They’re meant to allow you to manually make use of the filestore that Connect uses when processing a job. Connect cleans up after itself, however, whereas the things you store manually won’t be. So unless you’re also using the Upload File plugin, there’s really no reason to worry about the Delete File plugin.
Temp files always get deleted at the end of the process or before the next instance of the process gets executed. You shouldn’t need to clean up anything: even files that you create yourself in that temp folder (%t) will get cleaned up.
Note that the behaviour is different when running the process manually in step-by-step mode, where the Debug folder is used to create Temp files. But that folder also gets cleaned up at some point.
Let’s move this conversation out of this topic since it is not related to the original post and will only be confusing for any future reader. Could you please copy/paste your last comment into your original post (Optimize Embedded Images) and we’ll pick up the conversation there.