We set up an on-demand document composition server which is controlled through OL-Connect APIs only.
The server seems to be well tuned since during stress tests with multiple robots requesting multiple documents the 90th percentile falls within a few seconds of generation, between 2 and 8 seconds per document which is very acceptable.
However, I am noticing that sometime some requests take way more like 20/30 seconds, replaying the same request at a later time however results in a 3/5 seconds latency.
Given that the same request one time take 5 seconds and another time 30 seconds I suspect the Server goes to a “sleeping” state.
Metrics for each step (datamining, content creation, job, output) shows that the whole process takes longer like if each engine isn’t in a ready state.
Is this behaviour documented? Any tips on how to further troubleshoot the issue or optimizations on the Server settings?
There is no sleeping state to speak with, unless the underlying operating system forces it.
The two obvious suspects are the Java garbage collector and the Cleanup Service.
The Java garbage collector periodically runs at any given time, without intervention. While it is running, the system may experience severe delays. In most cases it should be nearly unnoticeable. But perhaps there is a usage pattern, such as high volume of requests, which worsen the condition.
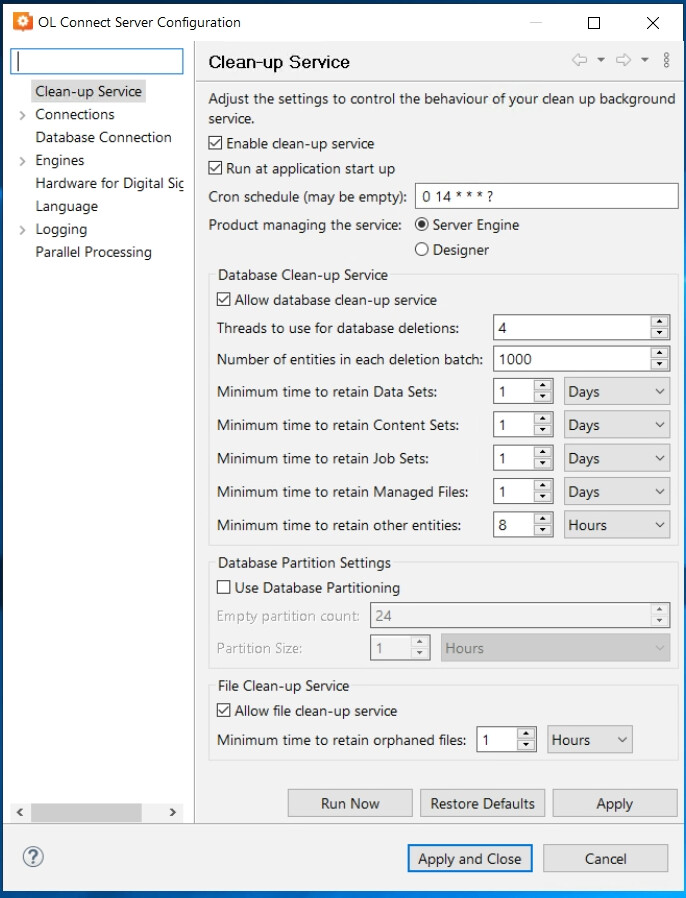
The Cleanup Service is a facility of Connect that periodically cleans up the back-end database from entities (data mapping records, intermediate content items, etc.) which are no longer in use. Its schedule is configured in the Server Congifuration application. During the time that it is running, the database can go under heavy load, which makes the overall system slower. Entries about the Cleanup Service being run should be visible in the main Server log, and it should be happen at predicable times (e.g. every 8 hours).
I had a situation where we restart the engines every day at 00:01 and the first Template to go through would take more than 30 seconds to execute. Since they are often triggerred by HTTP request, it would end-up in time-out from the user perspective.
I had to setup a process that runs every day at 1:15 am and generate a PDF. That did it for me.
Anyway as of now the clean-up should run at 14:00 every day, but the high latency happens at any time of the day as long as few hours pass since the last request. I am trying to understand how much time is enough to cause a lag spike.
As of now there are at most 20 request per day since we are still in a staging phase so for now usage patterns are to be excluded. However, synthetic stress tests with robots shows that the server handles well hundreds of requests (that’s where I built the latency statistics).
That could work for me too, as a workaround, but I need to better understand after how much time a lag spike occurs.
I’ll make a program to run a request at increasingly longer time delays, hopefully at some point the lag spike will show up and I will now how often to run a fake request.
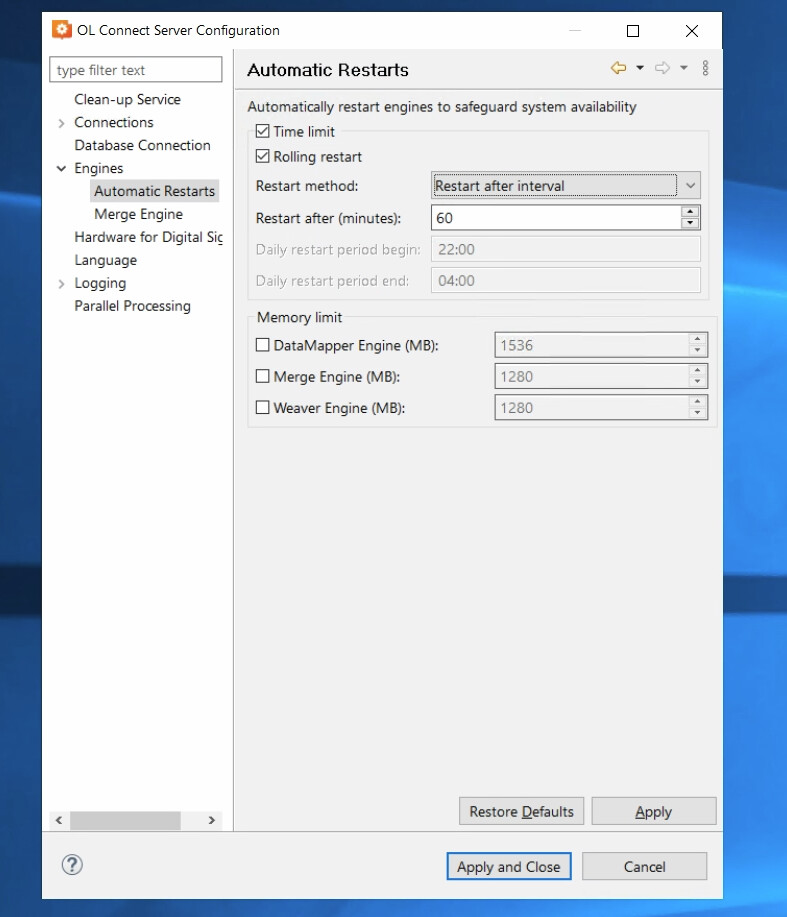
Might there be some correlation with the Engine automatic restarts?
I see it is configured every 60 minutes, does it mean at minute 00 of every hour? If not, when does the countdown start?
Side note: the lag spikes occurred at any minute, not at 00 of every hour. Maybe the 60 minutes countdown is since the last engine activity? That would stagger the lag spikes at different times.
I read the relevant documentation but I feel like it’s missing some examples or at least what would be the reasoning to be applied to choose the correct settings.
Connect is written in Java. As you may know, a Java program is delivered in an intermediate language which gets compiled on-the-fly (i.e. while it is running, not at startup or installation time) for the native hardware on which it is installed by a Just-In-Time compiler (a.k.a. JIT). During the time that the program is not yet compiled, it runs as an interpreted language, which incurs an overhead. Hence why Java programs get faster over time – the JIT improves the in-memory program as it executes.
The restart wipes out the JIT code from memory when the instance is shut down, and the JIT process has to start over when the new instance starts. During this time, the interpreted bytes run instead of the compiled code, hence the slower runs at first which become fast over time.
The restart mechanism was introduced when Connect was much less mature than it is today. It improved the general robustness of the system, e.g. by making sure that all memory is periodically reclaimed.
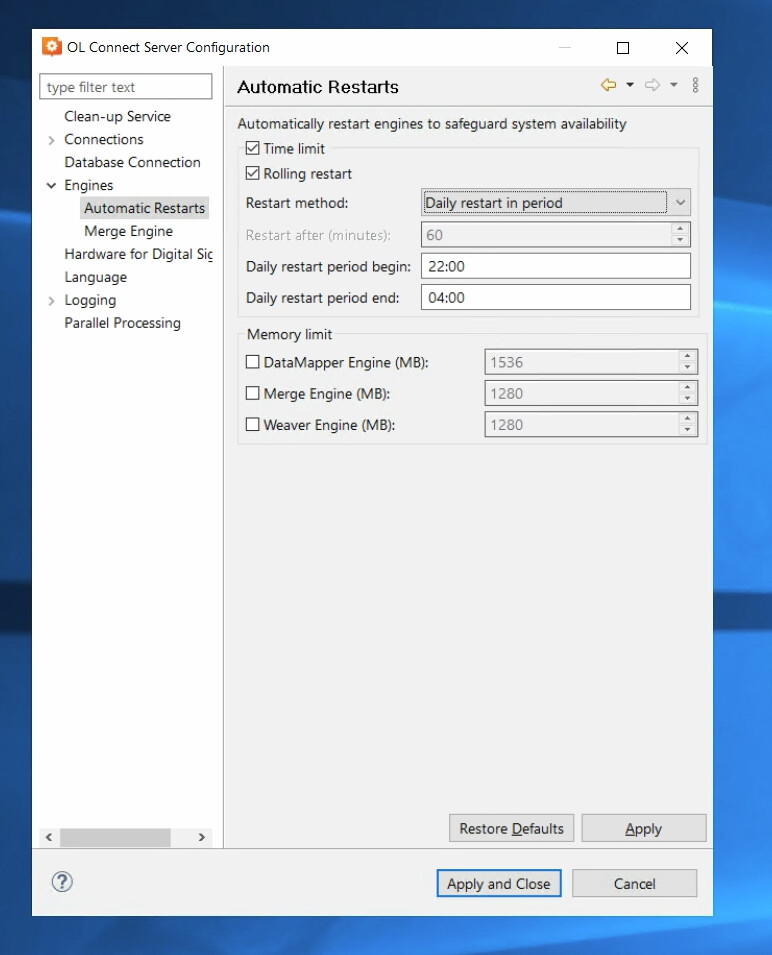
You can probably get away with increasing the restart interval, perhaps even scheduling it daily during the night. At the very least, you should increase the restart period. I believe that the default is 480 minutes. Not sure why you have 60.
Note: The restart after (minutes) refers to the time elapsed since the instance startup, not a time within the hour. Rolling restart means that instances are restarted one after the other instead of all at once. This is usually preferrable as it avoids a down time.
Thanks for all the feedback! I’m coming back to report updates on the issue.
We moved the restart to once daily and after extensive testing I can confirm that regardless of the server load the first request after an Engine Restart takes approximately x10 the baseline time.
We submitted the same request multiple times in different intervals before, immediately after the restart and at increasing time spans after a restart.
It didn’t matter at all how long after a restart the request was submitted, the first request after a restart is subjected to heavy latency increases.
The established baseline for the testing was a 3.4 second latency +/- 300 ms from file upload to the end of content creation.
We do not perform an all-in-one API request, but we call each endpoint separately with no additional business logic between each request except some logging which happens asynchronously.
As suggested by @jchamel I added a scheduler to execute some fake request after the scheduled engine restarts. Since I can’t know how long it takes for a restart I can’t take for granted to make a request exactly the second or the minute after a restart, so I make a bunch of them. This can surely be improved.
It would of course be ideal to have the OLConnect Server get back on its feets on its own
The main issue is that on a on-demand system, the Engine Restart might need to be executed more than once per night. If that situation arises, I will need to have restarts during the day. In that case, I have no way to be sure to be the first to make a request to the Server to wake him up.
I am coming back at the issue, unfortunately even after the fake request in the morning, the issue still persists. So the clean up service does indeed affect performance for the following request.
Data shows that the fake request did indeed make a change, however we are still experiencing random lag spikes. Is it on the OLConnect side or the VM side? Hard to tell. Telemetry collected with Grafana exporters shows low system usage so CPU, RAM, or Disk shouldn’t be the issue, but I would like to better pinpoint this.
What I have observed by adding timers to each olconnect step is that only the datamining and content creation step takes more time.
Below an example of two runs at different times of the same payload, template, dm etc
The long awaited new structured logging mentioned in another thread seems to be not released yet or I didn’t catch the benefits and would gladly like some guidance on how to ingest the logs.
I didn’t open a official ticket but maybe it could streamline the debugging for the staff?