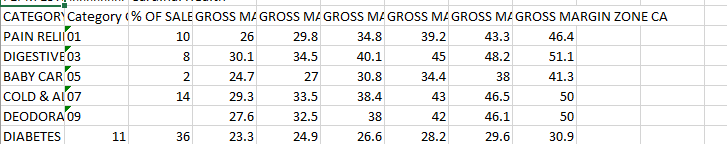I created a data model that works properly on a CSV with 9 columns but when I add additional source records that have less than 9 columns, those records don’t output properly in my template. I can’t figure out how to solve this problem.
Thanks again to all of those who have been helping me. I feel like I’m finally close to getting this project finished!
Unfortunately I’m not having any luck getting this to work. There’s no other way? Like a step in the loop that causes the loop to stop when there are no further columns?
Yes, there are other, much more convoluted ways to do the same thing, but I don’t see why the method outlined in the article wouldn’t work. If you give us a bit more detail on the issue you’re encountering or better yet, if you can share a data mapping configuration that demonstrates the issue, then we can try to help. Make sure the data has been anonymized, though.
I’m wondering maybe I’m not describing the issue properly. Let me see if I can explain a little better.
My employer gave me three spreadsheets, each with a similar set of data. Here is a screenshot of the first spreadsheet I used to create my data mapper.
The data continues on down the spreadsheet for about 30 more lines, and as you can see, there are 9 columns across. I created a data mapper for this document, and I was able to create a template in Designer where I could add in a dynamic table, and have the data from this spreadsheet displayed. So far so good.
I then wanted to test the data mapper by adding in the other two spreadsheet records, but when I do that, the dynamic table doesn’t display correctly for the other records. I presumed this was because there were a different number of columns.
The table goes to being just one row, with a bunch of errors in the messages pane.
Where I’m also getting confused is that for me, each sperate spreadsheet file is a record, not each line within the spreadsheet. It seems like the how-to sections regard individual lines as records, which is confusing me.
I feel like I’m so close to being able to finish this data mapper and all that is required from me after that is to make it look nice. I’m a graphic designer. I don’t work with data but my employer is trying to see if I can figure this out.
There’s plenty that could go wrong with your approach. Not only is the number of columns inconsistent across spreadsheets, but the column names are presumably different as well. So if you have an extraction for a column named “Category” but one of the spreadsheets doesn’t have a Category column, then the DataMapper will throw an error.
Now you could refer to all columns using their index instead of their name. It wouldn’t be very user-friendly for the next guy who works on your data mapping configuration, but it would work. However, it would still not address the issue of the variable number of columns.
Here’s an example of a DM config that uses the technique described in the article quoted above. I still believe this is the best approach. Load it in your DataMapper and you’ll see that by default, only two columns are available (because the first CSV line only contains 2 columns). When you run the Pre-processing script, the number of columns is extended to 6 and all the data can be accessed as expected.
Note that you only need to manually run the preprocessor while editing the DM config. When calling the DataMapper from Workflow, the preprocessors are always executed automatically.
Hi Phil. I thought for a minute I had this figured out but I’m still hitting a snag. Would you be open to me sending you a link to a screen capture video of what I’m doing?
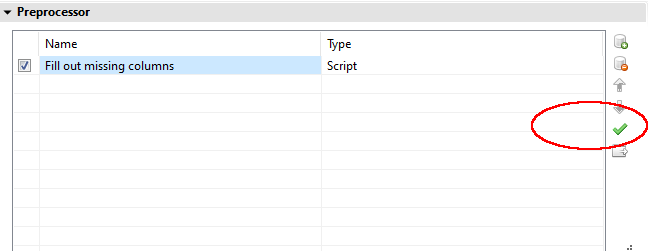
You never ran the preprocessor. As I said in my previous post, at Design time you have to manually run the preprocessor. Tick the preprocessor script, then click the check mark icon :
Thanks Phil, but I may have to throw in the towel on this. I’ve tried all these steps in every different order and I can’t get it to work correctly. I’ve even gone back to the article you sent and tried following the steps verbatim. Somewhere I’m just missing something. If you’re interested, feel free to send me an email to danzarwell@gmail.com. I’d probably be willing to work out some kind of consultation fee if we could screen share and get this figured out. I appreciate all the time and effort.
I can’t do that, but you have a couple of options: you can either contact our Support Team to see if they can help you out (I see in our systems that your OL Care is valid) or you can also ask your Customer Satisfaction Manager to put you in touch with our Professional Services team.
I contacted support and apparently they are putting somebody in contact with me, but I wanted to show you one more screen capture because I think this will really solve the issue. I have no problem getting the script to work on the sample data, but when I load in my data and run the script, the dynamic table still only shows 6 columns, when there are more than 6. I thought maybe I needed to add the additional columns to the detail table steps, but that doesn’t help either.
You are misunderstanding how the DataMapper works. It will not automatically extract a new column when there are extra columns in the data because then the data model would not be consistent from one data file to the next.
The DM always extracts only the number of columns you specifically told it to extract, which in your example is 6 columns. If you want to extract columns 7 to 9, then you need to specify those extra fields in your extraction task.
If you know for sure that none of the CSVs will ever have more than, say 12 fields, then you could modify the preprocessing script I provided in my example so that it always adds up to 12 empty cells to each CSV row, and then your extraction task would always extract those 12 columns.
The script would look something like this:
// Thanks to awwsmm for this clever RegEx
// https://gist.github.com/awwsmm/886ac0ce0cef517ad7092915f708175f
var re = new RegExp('(?:,|\n|^)("(?:(?:"")*[^"]*)*"|[^",\n]*|(?:\n|$))','g');
var maxFields = 12;
var oneLine;
var inFile = openTextReader(data.filename);
var outFile = openTextWriter(data.filename+".csv");
while(oneLine = inFile.readLine()){
outFile.write(oneLine + ",".repeat(maxFields-getNumberOfFields(oneLine,re))+"\n");
}
inFile.close();
outFile.close();
copyFile(data.filename+".csv",data.filename);
function getNumberOfFields(str,regex){
var match, counter=0;
while(match = regex.exec(str)) counter++;
return counter;
}
Note also that in your template, you will have to build a table that displays those 12 columns on your dynamic table. Again, the Template is not able to simply add extra columns to the table if there are extra columns in the data (imagine if you designed it for 6 columns and then all of a sudden there are 50 of them!).
Ok, I think that is the answer I was looking for. My employer wants me to build a data model that will output a print file showing the data from a CSV file, where the print file will adjust itself accordingly to how many columns it sees for each individual record. Sounds like that isn’t really possible, and I will need a different data model for records with different numbers of columns.