Is it possible to re-group documents after a data mapper in a script rather than having to output sorted then read back in?
Basically I have a PDF coming in where I am splitting into documents, I then need to merge documents for the same address together. So I’ve got a data mapper then a metadata sorter on the address but how can I regroup?
Have you already consider the option of grouping documents on Document Set level based on the value of the record field “Address” and to split the documents on Document Set level? In that case you have to apply, among others, the following settings:
Job Preset:
“Use grouping” option checked in the Configuration Selection window
The record field “Address” moved from the Available Fields to the Selected Fields overview inside the Document Set Grouping Fields tab of the Grouping Options window
You can create a Job Preset via: Connect Designer > File > Print Presets > Job Creation Settings…
Output Preset:
“Separation” option checked in the Print Options window
Separation option “Document Set” selected (dropdown menu) in the Separation Options window
You can create a Output Preset via: Connect Designer > File > Print Presets > Output Creation Settings…
Yes we currently do that on a lot of jobs, however after we have sorted and grouped we then need to add text onto the page for production marks etc (eg Page N of N). So we we have to output the PDF sorted, then within a mapper regroup based on the address changing, then we can add N of N text in the template. These jobs can be rather large so outputting and then reading back in adds a lot of processing time in as PReS doesn’t process PDF’s very quickly that have lots of images etc in.
So that’s why ideally I’d like to do this after the mapper in script so we don’t have to output to read back in again.
Have you already consider the option of using the Metadata Sorter Workflow plugin to sort the records on the record field “address” and using the Metadata Sequencer Workflow plugin to split the records based on the changing record field “address”?
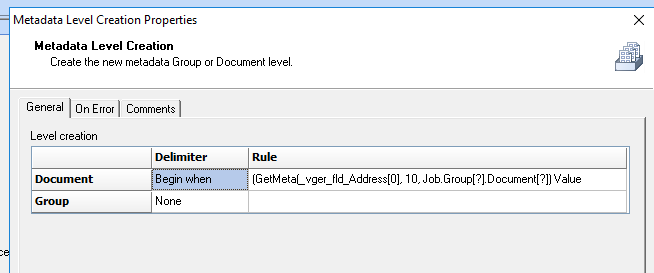
I’ve just tried that but it doesn’t appear to be working as the documents that have the same address aren’t getting changed. Below is the rule it’s generated. Is that correct?
I can see 3 documents that have the same address but after the level creation it’s still the same? I wasn’t sure what the 10 was for in the rule and if that needs changing?
I assume that you don’t need to make use of the Metadeta Level Creation Workflow plugin. Please let me know if you are able to get the expected result by using the Workflow plugins (plus Properties settings) as shared in my previous comment.
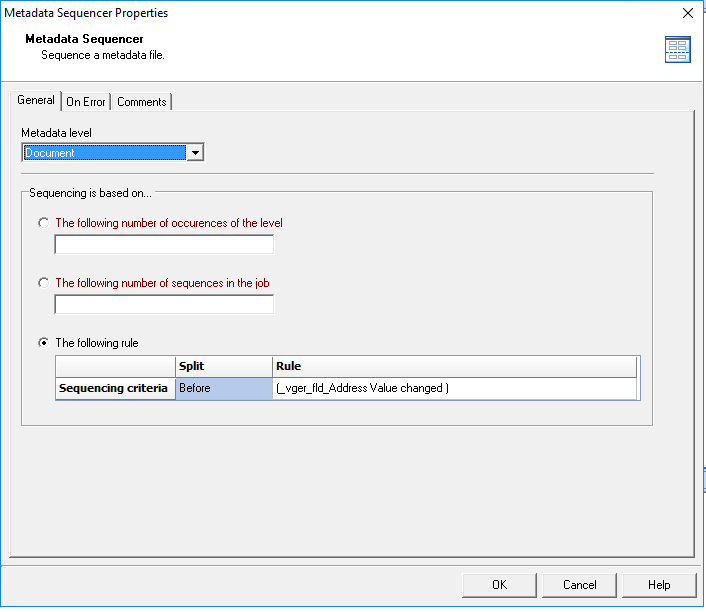
Sorry I was using the level creator instead of sequencer. I have just put in the sequencer with the below settings but I’m just getting 1 document group now
Can you let me know please how many different Address records field values are there when using the specific PDF document as input data? And how many records of each “different Address records field values” are there?
35 records (which does contain the Address record field) I assume? And I assume that you have executed the Metadata Sequencer Workflow plugin after the Metadata Sorter Workflow plugin? If so, can you let me know please how many records (documents) would you expect that the metadata of the first loop/run of the Metadata Sequencer plugin will contain?
Is it possible for you to share the PDF input file or does it contain sensitive data?
I’ve just re-created a simple PDF file with just 5 addresses in that should create 3 documents as such. Also attached is the mapper etcTemp.zip (86.7 KB)