I have a simple txt file with 79 lines, and I need to split those lines based on data in each line.
I’ve attached a sample datamapper where the page delimiter is “OnLines” and it creates a new record for every line. The boundary trigger is “On delimiter”.
If you change the boundary trigger to “script”, which contains a single line boundary.set(), everything stays the same, still 79 records. Add a single space in the boundary script and execute it - number of records changes. Another space, and execute - number of records changes again.
I think that is a bug in datamapper, but I need to confirm it, and hoppely get a workaround.
We are using Connect version 2024.1.1
Here is the video.
I tried several times but this time every single time I changed the script it went directly to 1 record. Few times during initial testing it first dropped to 9 records, then 4, and eventually 1. All I did was add a single space in the script and apply changes, and the number of records changed. I guess you have to believe me on that
I just noticed in the video that when the number of records is displayed as 1, the Text viewer’s display doesn’t change… but if there were only 1 record, then it would display all 79 lines in that viewer.
So part of the DataMapper considers there are still 79 records (the Text viewer), while another part considers it contains a single record (the Data Model). So the issue is almost certainly due to a missing refresh in the Data Model pane.
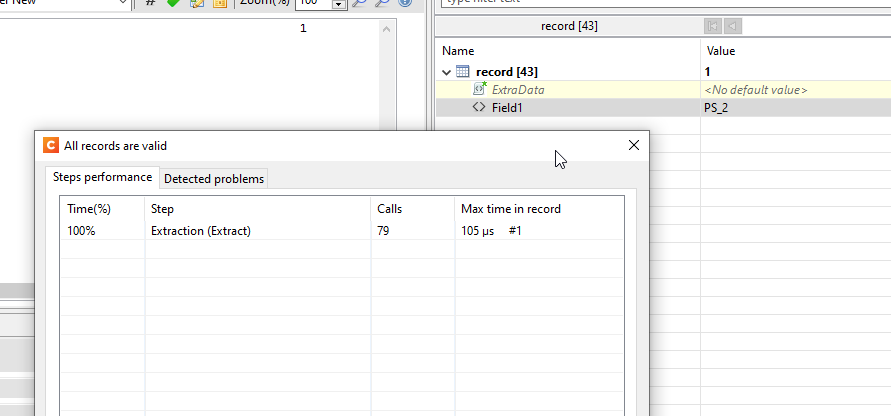
Try the following: when the record number is displayed as 1, click on the “Validate all records” button in the toolbar to see if it shows that there are indeed 79 records:
File is UTF-8 BOM. I convert it to other encodings but the results are the same. I also added some random files from my PC, no change in behavior.
We’re using boundary.set on more than one application (I think all of them are PDF based) and never had an issue. This is the first time we need this on TXT file.
Validate all records show the correct number of records.
OK, so it’s definitely a refresh issue then. I’ll have our development team look at it. Perhaps they can find a workaround, if they can replicate the issue.
But at least, we know that the DataMapper knows the actual count of records, even if it doesn’t display it properly.