I’m using PDF splitter to split pdf into smaller ones. My first page indicator is page number, like 1, 2, 3, etc.
I want to split before page 1. But if there is a page number 11, splitter also splits pdf.
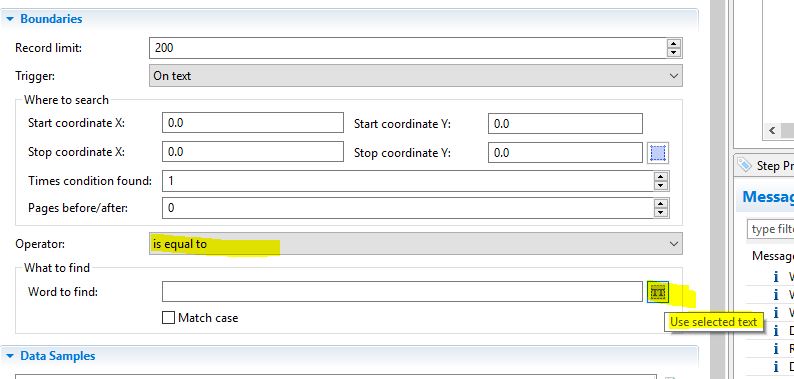
It looks like comparison method is split if region contains value, is there a chance to change comparison method from contains to equal to?
The idea is to set the page number in a metadata field. Then, still using the PDF Splitter, you will Split PDF file based on Metadata, at Datapage level, following a rule which will compare your metadata field for you page number to the number 1.
In matters of steps in Workflow:
Create Metadata
Metadata Fields Management (here you create your pageNumber field and assign to it your page number at on Page level)
The boundaries operators list does contain a “Is Equal To” operator.
Now, the trouble with that with PDFs is that you may not always get “1” in your region. Depending on how the PDF is encoded, you may get "1 " or something else.
So, to be sure you’re looking for the right string, select the region that will contain the entire page number (not just the position of the first number, but all possible numbers) and then use the TT button to copy the exact value that is present on the first page.
Then, even if page 1 is really "page 1 " in the PDF, your Is Equal To condition will match the 1 and the extra characters. Of course, even if there aren’t extra characters, the is equals to is not going to match on “11”.
You’re going to need to use a metadata based split in this case.
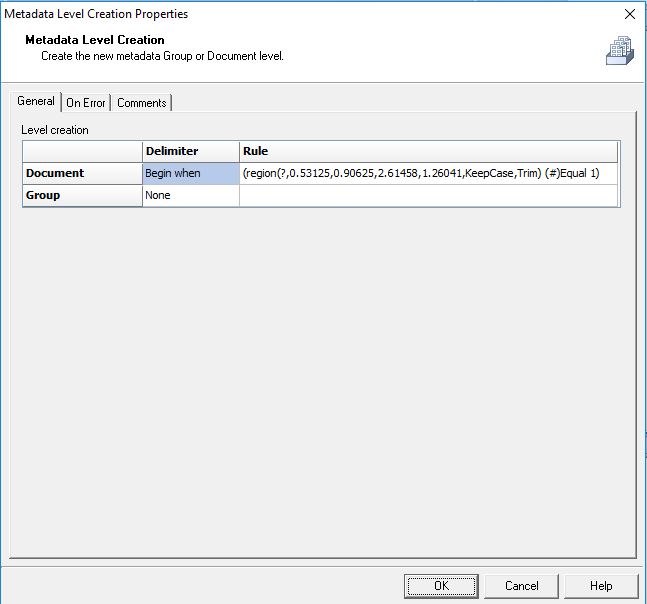
First, run the PDF through a Create Metadata step in passthrough. Next, you’ll run it through a Metadata Level Creation.
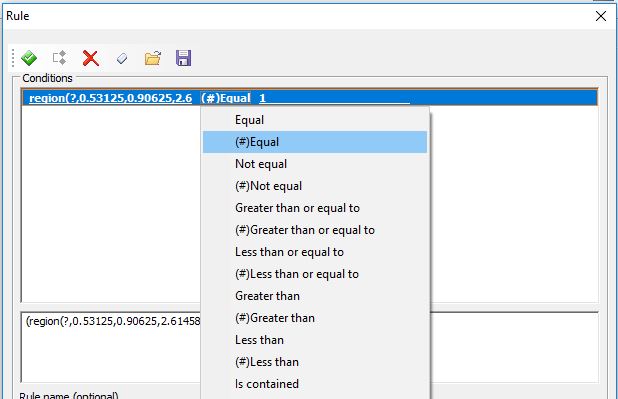
In there, you’re going to specify that a new document starts when Region is equal to 1 (make sure it’s a numerical comparison) where region is the area on the page with your numbers.
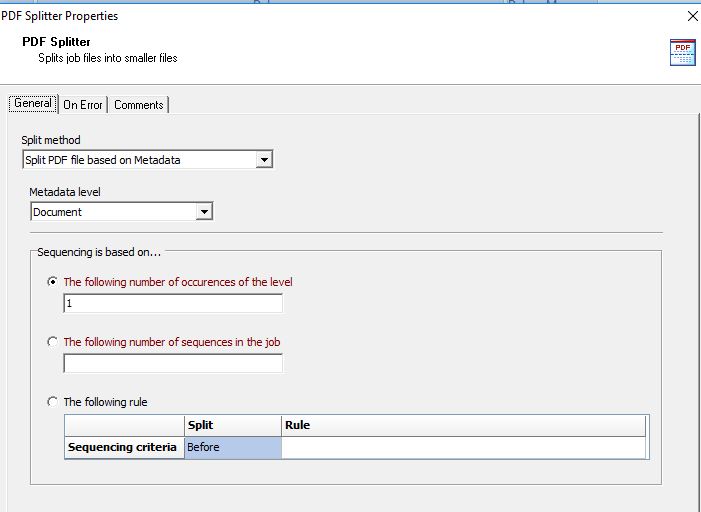
Finally, you’ll run it through the PDF splitter and split based on metadata at every 1 occurance of the Document level.
I’m not sure if all my data files are valid, bo one of the files returns an error during split. All other files are splitted correctly using above solution. But this one that produces an error is as below:
W3001 : Error while executing plugin:
W3671 : Move file <C:\ProgramData\Objectif Lune\PlanetPress Suite 7\PlanetPress Watch\Debug\tmp01036F43F30AQ4EE9EB1D.pdf>
to <C:\ProgramData\Objectif Lune\PlanetPress Suite 7\PlanetPress Watch\Debug\spl01036F3S2TW6M18E8DF4B.dat>
failed: Error code 0: The operation completed successfully.