Yes, we’re working on PDF processing and looking into Alambic support, but there’s no ETA yet. Our current focus is on Windows Printing support, with PDF editing likely coming after.
To split documents, you can use a data mapping configuration to set boundaries. This can be applied in either the Data Mapping node or the Document Mapping node. The Document Mapping node is used when input data is sent directly to a job (or output) preset, skipping the content creation step. This helps speed up the process when personalization with an OL Connect template is not required. This method is commonly used for splitting, sorting, grouping, or adding extra content like text, OMRs, or barcodes to individual documents, all managed by the output preset.
Noob question: Using what you stated above, will concating the ouptut split PDF be possible? I use Workflow PDF splitter/Send to Folder-with concat on to do this since the Connect presets error out when a file already exists. (I have to concat split PDF’s due to merging accounts that have the same account number while using said account number as the file name) [note that recipients with multiple accounts dont always follow in the data]
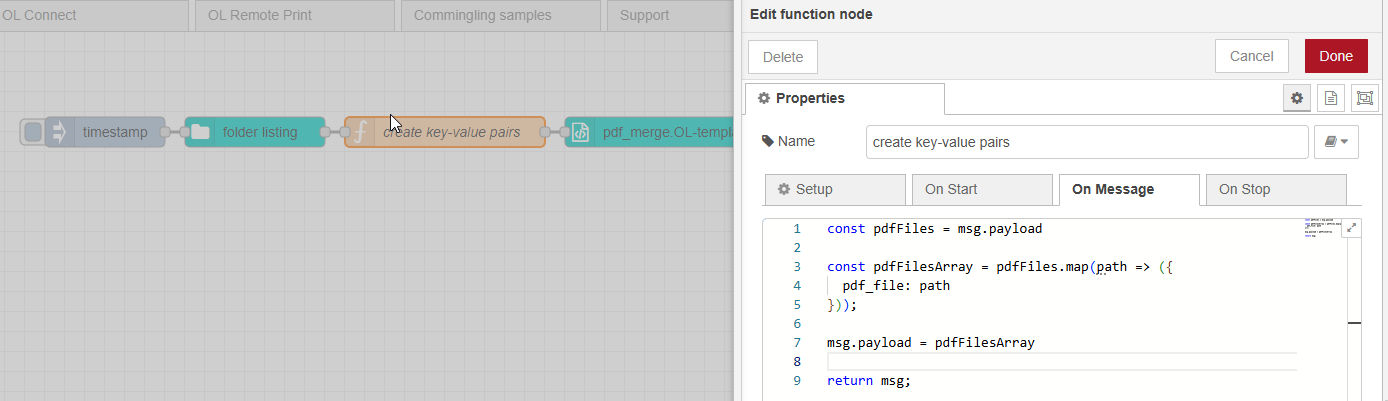
@Sharne; The Data Mapping config approach can be used for splitting PDFs. While OL Connect nodes can concatenate PDFs, they might not be as efficient as before (today). Here’s an example flow to inspire you:
The flow uses OL Connect 2024.2, which allows bypassing job creation and directly feeding content to the output engine.
It starts with an inject node to trigger the flow, then a folder listing step collects the paths of all PDFs. These paths are then converted into key-value pairs using a function node, with the key matching a field in the “merge template” data model.
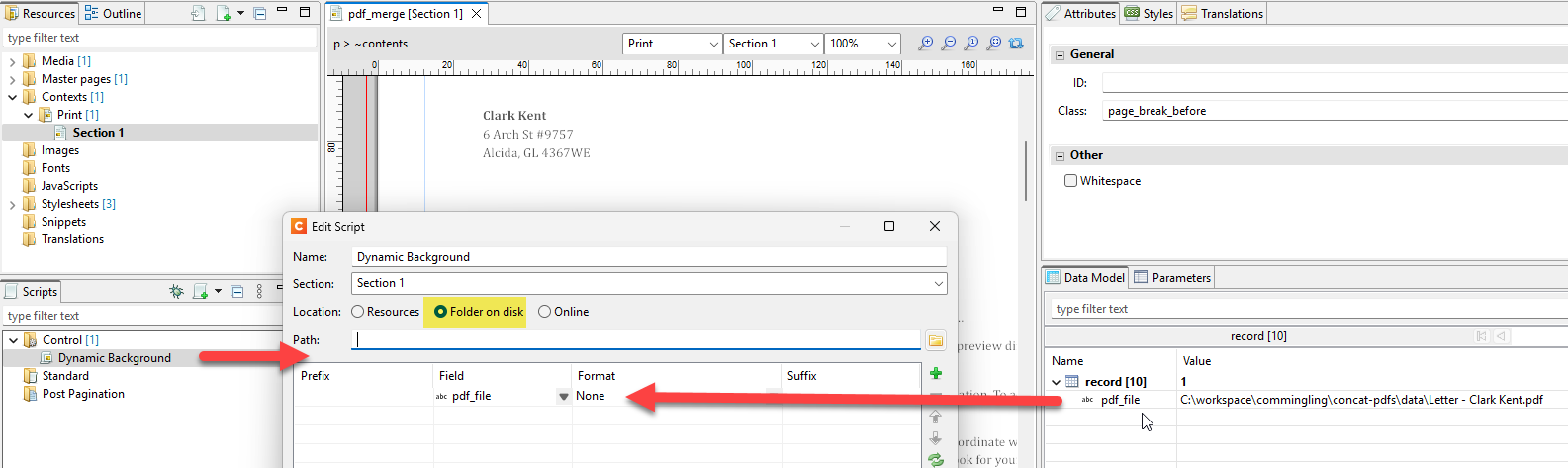
The template sets the PDF path as the section background, automatically generating a page for each PDF page. You can add a running page number with a master page or even use stationery backgrounds through the Media and SheetConfiguration options.
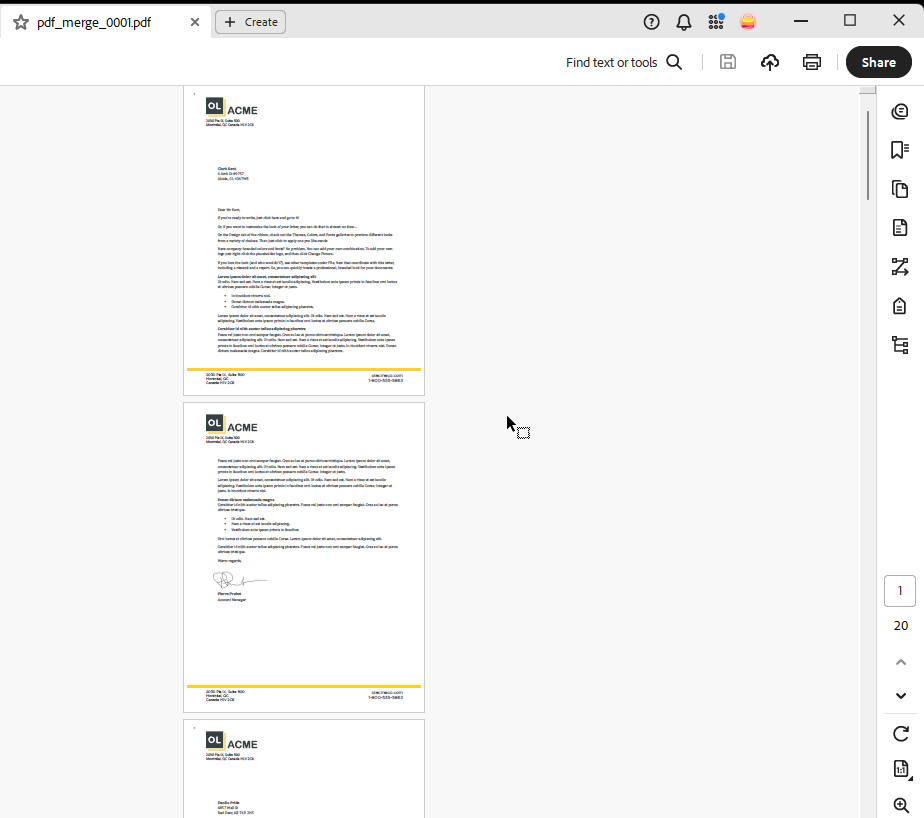
The Paginated Output node is set up with a generic PDF output preset, and if using stationery, you can enable the “print virtual stationery” option. This preset generates a single merged PDF file.
FYI: I found that this node, node-red-contrib-pdf-merge, works well for PDF merging. It can directly consume the payload generated by OL’s “folder listing” node.
I imagine the thinking behind even using NodeRED in the first place is so that OL/Upland can focus on creating nodes that are directly tied to Connect Resources and Managed Files, without having to create more generic processing nodes, since those already exist. Simple SMTP emails, PDF merging are two examples.
Thanks for the sample flow. From my little understanding, this flow will merge PDF data from a hot folder. However, my question was not refering to PDF merging per se.
I have many statement runs that uses line printer data. So I use a Connect data mapper and template.
In Workflow after the Create Output plugin I have a PDF splitter plugin. I split the Connect output and rename each PDF using the account number from the statement. Now due to some recipients owning multiple properties I have to set the Send To Folder Plugin to Concatenate files so that all statements with the same account number are in the same file. (as mentioned above, these accounts don’t follow each other in the data. Account xyz might be record 523 or record 88236.)
The reason I ask is because I cannot use Connect plugins for this as they don’t allow concatenation and error out with “file already exists”.
I have the same situation and solve it with a “Sort on” the account number field in the Datamapper (not available with all data types, but mine are CSV files so it’s an option). Then my data boundary when the account number changes.
That said, I agree! PDF merging and PDF “send to folder, concatenate” is crititcal to a lot of workflows, so a mechanism in Automate to provide that functionality would be welcome.
Yeah, I have to have that functionality too. I cannot use data mapper sort as it is not available for the data type I get most. Will wait to see what OL has for this scenario. (I’m not writing preprocessor scripts for this, if Workflow is to be replaced then all old functionality needs to be in Automate too imo.)
I largely agree! I need the equivalents of “Create File”, PDF splitting and merging, a folder listing that accepts a dynamic/variable search mask/file spec, I need data selections out of the “job file”… I need a data mapping module that doesn’t require a round-trip into and out of the filestore… and so on.
It’s pretty exciting to see experienced customers getting as worked up as we are in this new technology.
As Erik already mentioned, providing an equivalent to the AlambicEdit API of Workflow is very high on our list, whatever the form it will take.
As for the other features, we know that there is still a lot of things we take for granted in Workflow that are not yet available in Automate. Rest assured that we are hard at work at adding as much as we can.
But there’s the other way around, i.e. stuff that Workflow doesn’t do. The full, modern JavaScript runtime and libraries? The web-based editor? That’s pretty cool.
I’m trying to stay ahead of the curve! I have about 4-5 main “patterns” that occur frequently in my work, and so I’ve been implementing them in Automate as best I can. So far, I’ve been able to implement my 4 main process patterns:
One Data file, archive it, produce 3 output “streams” (single PDF for print and mail, single PDF for customers opted-out of physical mail, one PDF per statement for archival and distribution to various document repositories), SFTP the print file.
Two data files, two sets of resources. The 2nd set of resources uses output from the 1st set (dynamic background script to pull the PDFs onto a Print Section). Archive, same 3 output streams, SFTP etc.
Jobs that require manual QC: output to “pending review” folder, send SMTP email to reviewers. After QC, edits, and approvals, drop the copy of the original CSV data file (saved in “pending review”) to a hotfolder. Archive, generate output streams (including a merge of all the pending individual PDFs, some of which may have been edited during QC, to generate a print and mail batch), SFTP.
NODE.js input processes, various requirements, including folder listing, Connect resources to generate HTML, etc.
I’ve been able to implement these in Automate to produce the same results as the corresponding Workflow processes.
The only process pattern left involves custom Pitney Bowes plugins to generate statements with a Certified Tracking number. Those are all based around legacy metadata, so hopefully your vendors are actively working on Node-RED nodes for their plugins!
@Sharne Reading through the comments and going back to your question on statement runs. I believe the solution to this isn’t tied to the automation environment being used. You can simplify the process by utilizing Job and Output Presets. Here’s how you can approach it:
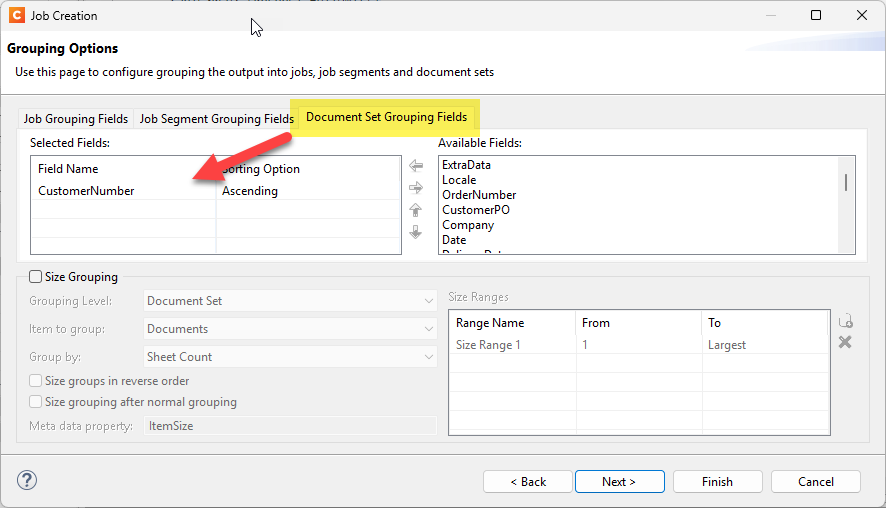
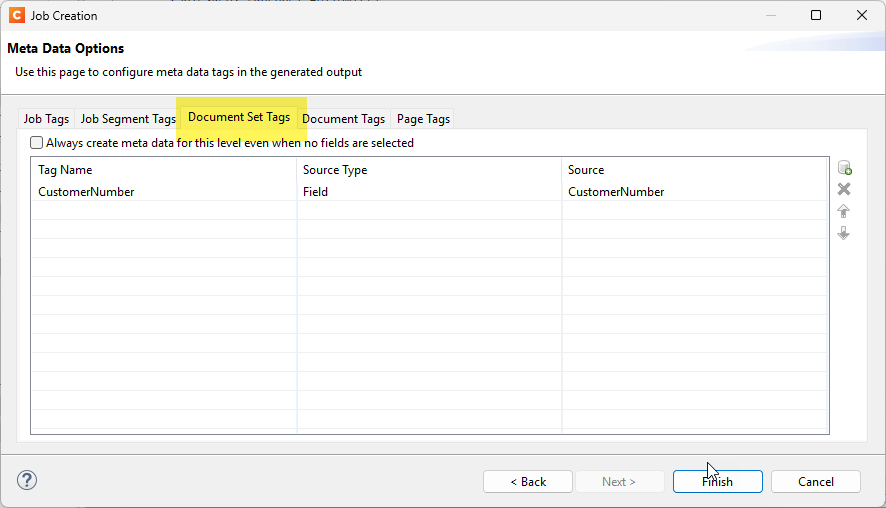
Create a Job Preset to “Group” documents based on the account number and tagging each Document Set with the account number. Optionally add “Sorting” to put the statements in a specific order.
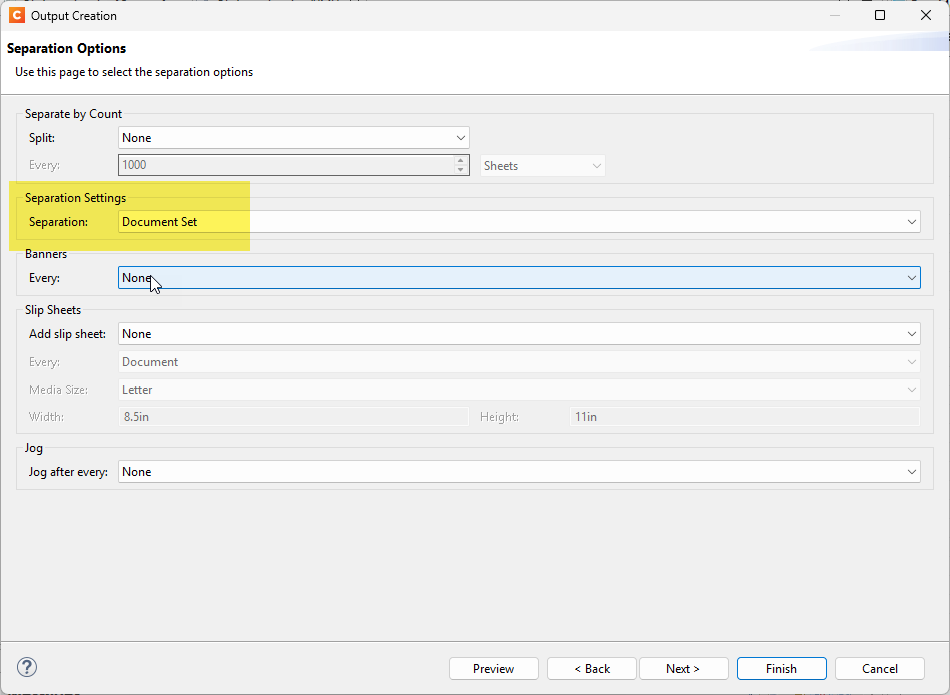
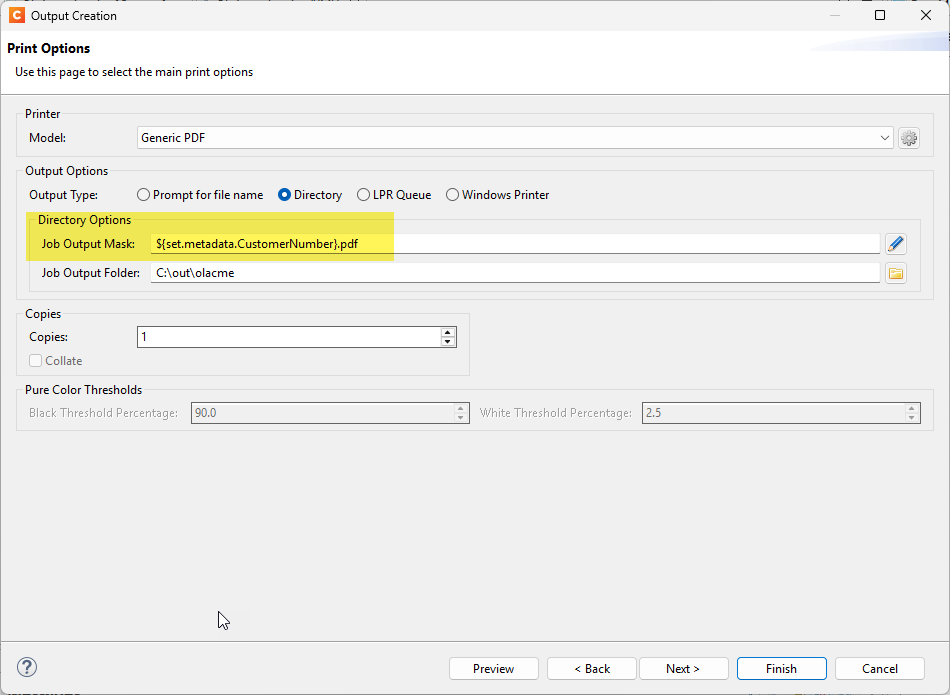
Use an Output Preset to split the output by Document Set and configure the Job Output Mask to incorporate the document set metadata (account number) into the output file names.
This method is effective whether you’re using OL Connect Workflow, OL Connect Automate or print directly from the Designer.
I’ve attached a package created in 2024.2.3 to illustrate this approach. There quite some interesting things you can do with Job and Output Presets.