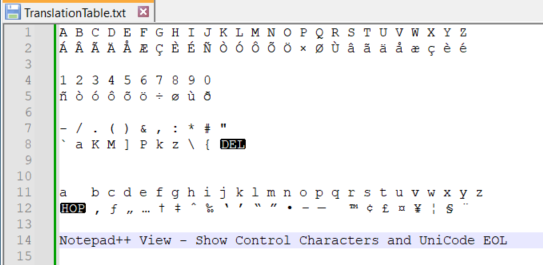
I’ve encountered a bunch of PDF files that appear to have been created using a font that have a custom encoding scheme.
If the fonts are embedded the extracted text from the text layer results with these expected text values from the image.
If the fonts are not embedded the extracted text from the text layer results with these unexpected text values from the image. I believe that this is due to the custom encoding scheme.
I’ve copied the values and built a table that I believe is correct, although missing 2 characters.
Is there a way to convert the scraped text that goes into my fields.
The scenario is one huge PDF that is being separated into multiple documents and then using the extracted fields to name the output files.
Hello @UomoDelGhiaccio, can you let us know please if you have found a solution at the end?
I don’t think that it is possible to achieve what you are looking but perhaps someone else has come across this issue in the past and have found a solution for it?
Only some of the PDF files being processed have the weird encoding.
At the moment we are identifying if the PDF files being processed have high ascii characters and flagging these files for review. At some point we have to deal with them, but processing the backlog was deemed a higher priority.
We are extracting data from the PDF files for an EDM system, so the current plan is fix the data in the CSV file that we extract and leave the wierd encoded PDF alone. They search off the index fields in the EDM so the PDF files don’t need to be text searchable.