I have read many posts in here about workflow being 32bit app and issue with out of memory when processing big jobs.
I have a process that gets triggered via Capture folder. I thought that if I could somehow split the process via branching, I can circumvent the limitation for eg:
First file dropped in a folder runs the process and 1-25% of the progress it will skip all branches until the end. Then drops another file in the folder capture but this time it will skip to 25% until 50% until the end , drops another file and so forth.
This approach doesnt work and Im still getting the out of memory error.
Is there any other way to circumvent this? So the process is not interrupted and finish by itself without intervention. I find that if I drop the file to trigger one at a time. It works. I suppose it gives workflow time to free up memory??
There is unfortunately too little information to provide with any useful tips. You’d have to tell us what kind of data files you are processing (type of data, average size, etc.). And you’d have to explain what kind of process each file goes through. Workflow can easily handle thousands of files, but then again it could very well choke up on just a few if the process is extremely complex.
I have found over the years that in most cases where memory becomes a problem, it’s because the processes have become very long and convoluted over time. It’s almost always better to have shorter, targeted processes. But there’s no magical wand to convert a Workflow configuration. The processes have to be analyzed and possibly redesigned.
I don’t think this is something we can do on this forum as it would probably require you to share sensitive information. You might want to contact our Support team instead.
I have already contacted support prior to this. And have passed relevant info.
What Im looking from this post is to have collective/general knowledge of efficiency so that workflow doesnt hit the ceiling.
The process in question does have very intrinsic requirements:
Record count: 65000
It needs to process RAW(dirty) client file, converts/manipulates,extracts to separate channels (digital and print) , groups all items to DLX,C4 and Box sizes in consideration of inserts, sort them through postal software, reports on each channels and bundles for production and client purposes and be split the final output to individual pdfs for digital channels.
This is the summarized version of the process: Important note here the tasks in process are mostly running external program , only the connect tasks are pdf generation and data mapping configuration.
I have surmised that this should be an efficient process, as Im letting the bulk of the data process/routing of files/generation of reports to an external program.(.NET program) but without a concrete evidence I cant be sure.
For eg: Merge Task in workflow took 1.5 hours to finished, where I let an external program to do it, it only took 10 minutes. So I have replace the task with that.
These are the sort of thing Im looking for. And I thought splitting the process to section via Capture folder would work but from the log it seems only 1 process has ran. Meaning having a capture folder at the beginning of process to trigger still constitute as 1 process as more files are picked up.
Hope Im not talking non-sense If I am apologize. Any insight to this is appreciated.
I am extending my post. As I have been with support and Connect specialist with this.
What have been suggested was to chunk the files and put it in a self-replicating process.
To review. We have around 65K-70K records to process with a very complex datamapper/template with value calculation , manipulation and cloning to boot.
I have split the records to 2500 hoping to pass into self-replicating process without failing due to memory issue. I have ticked the option to prioritize memory before performance and minimal logging.
I am aware of the 32bit limitation and upcoming Node Red. But at this instance we have a lot of work to even have time to look at this. I am looking for ways to manage memory better in Workflow as original post.
Prior to making this change using one process to do everything it took around 8-10 hours. With self replication approach it took around 4-5 hours almost 50% improvement in run time. BUT this is with “Out of Memory” issue. I only manage to complete the process because I set it in a way that can be continued where it left off by means of manual intervention.
I made a ton of changes to make the process highly optimized to get workflow process to basically do Connect plugin tasks only.
Also I noticed restarting Workflow service as mentioned reclaims the memory. This seems to enable the process to run without a hitch.
Currently , the only memory issue happening now, is in one of our script that reads
var metaFile = new ActiveXObject("MetadataLib.MetaFile");
metaFile.LoadFromFile(Watch.GetMetadataFilename());
We need this to generate MRD and recon report files. My question now is there an alternative way to reading datamapper field values without doing this. As this is obviously contribute to memory usage?
Better yet if somehow there is a way to force reclaim/cleanup memory after a process has finished in Workflow? It could be anything like calling a function, purposely deleting a file somewhere. Even illegitimate way of doing it will do or running an exe program perhaps to do clean up.
At this stage its ridiculous that the only decision to make is move away from using Workflow when a lot of work and time invested learning and creating processes with it. Telling customer to use Node Red is unrealistic. Could we perhaps get a Watch.FreeUpMemory(ProcessName) function to call in the next iteration to target clean process thats already concluded.
Surely there must be a way to force the memory retake/clean?
I am the lead developer of the team which, among other responsabilities, maintains Connect Workflow. I would be interested in having a closer look at this specific issue you are having.
Do you think it would be possible for you to provide us with a simplified, streamlined, anonymized if needed, Workflow configuration and all related resources which isolates this specific memory issue you are having and would allow us to recreate it synthetically?
More specifically, what I would be ideally hoping for is something like a 4-5 step Workflow process, some Connect resources (dmconfig, template, etc.), “run the process with this data file and see it blow up”, kind of setup.
In understand that you have already optimized the hell out of your entire solution, so I am not looking to start from scratch, but really address this specific memory issue – if we can.
Please let me know if this could be a possibility, and we can make arrangements on how to proceed.
Added – You may have already provided part of all of the pieces I am referring to in a support ticket. I am sorry to duplicate the effort if that’s already the case.
My colleagues from Support are more than capable of handling many complex cases on their own, so things don’t always get escalated to us. On the other hand, we in R&D obviously have deeper access to the knowledge and internals of the software, which allow us to work more directly on specific issues.
This will prevent the process from flushing all the log messages to disk at the successful end of the process, which can be a fairly time-consuming operation.
Second, if you don’t need the metadata, don’t use it. The process of converting the return value from OL Connect REST calls from JSON to Metadata can be time and memory consuming. Metadata is practical, but if you can avoid using it, then you don’t need to go through that conversion process.
I understand that you need some of the info from the extracted data to build the MRD file, but it would probably be more efficient to use a direct REST API call to retrieve that information.
I have indeed put a huge time sync weeks to months making this workflow/process optimized. Have in contact with Ch*** upland support specialist and explained the requirements.
I am a developer as well to keep on subject. Without repeating our requirements I have mentioned above.
Heres what Ive done to take off memory load our workflow process by using a separate external program.
Any data mapping manipulation for non-structure client file I have do away calling an external program instead that I written in .NET, where I use datamapper before to convert such files that took hours to complete to a mere seconds to minutes.
Any merging of PDFs is now handled by separate .NET program also huge time savings.
PDF Splitting is now handled by separate .NET program again huge time savings.
Reading of files through workflow
Aggregation of records of same address be grouped together
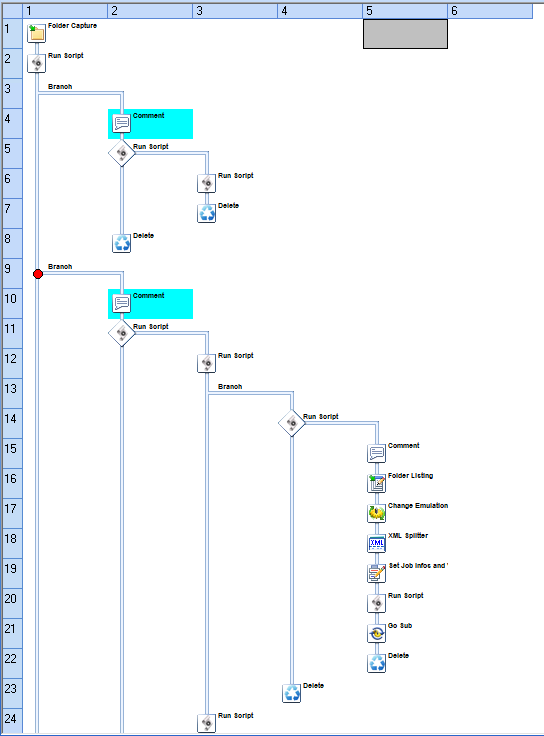
Basically now the process goes through branches and calls external program to pass on the responsibility, I made the process section by section so if ever it is to fail I can drop a “state” file and jump off different branch without starting from beginning.
I made the process script centric to avoid having to update the configuration all the time.
This ^ process now when it reach the “printing” branch collates and chunk all data to small pieces and copies them to another hot folder, where a self replicating process will take over and run Connect tasks eg generating pdf outputs and report. The original Main process exits immediately after.
Doing this hoping to allow workflow to work on small chunks and avoid hitting memory limit.
Another thing I noticed is when the Workflow is up and running all throughout the day with other process that goes in an out. When my big QTY process turns to process this usually results Out of Memory issue. But if I restart the workflow then I trigger the process its usually a good outcome.
This tells me that workflow seems to accumulate memory throughout maybe gradually freeing them.
Also I have just ran a small job in Workflow after finishing this big one. This small job now runs out of memory as well. This really seems to compound accumulation of memory usage even after a big job has successfully finished. If this is the case, there really isnt anything to target to optimize as the memory issue could come out anywhere in the process and the only solution is to restart Workflow to force it to free up memory.
Here is the breakdown on how I set my Workflow Processes please bear with me.
Job A arrives with 70K records - raw non-structured client file. Channels: Print and Digital (Email,Bpay,Sniip)
Main Process - Polls a folder for a client file.
Picks up client file.
Creates temp folder, puts the file there.
Runs a custom program to convert the client file into CSV file.
Runs a custom program to manipulate the CSV (inserts any custom process per requirement)
Normalises file, injects unique ID, parse address fields, do lookups.
Extract Email,Bpay, Sniip records
Remainder becomes Print records
Extract Overseas and Unmailable records from Print Records
Each extract data file is then aggregated by name and address fields. All like name and address are grouped together with a unique identification.
Each extract data file creates header file for Sorting through Post Office software, if the data is multiline it also takes into consideration. Once sorted all is put back together as a multiline data with each file per Channel.
Print data now needs “pre-print” to separate any records that fall under 1-6 , 7-20 and 21+ sheets. It does it by splitting the data to smaller chunks 2000* per file. Count the chunks and create a ini config with all variable for processing. These files are copied over to another folder for processing. The main process skip all branches and finishes. Pre-bundling print: Self-replicating Process
These prints these small chunks,reading the metadata and getting contentsetID, queries API for the sheet count. Once all files are finished. Data files are generated as group of 1-6 ,7-20, 21+ sheets records and they are all merged together to form 3 sets of files. This process checks a flag that all files are finished and sends a “state file” to the main process. To keep processing where it left off.(PDFs are stored in file via Output Preset)
Back to the main process - Now it collects all 3 set of files and sort them again via Post Office software, these 3 sets of files are again broken down to small chunks. This time it also collects all digital records, to be generated as well. And passed to Print self-replicating process.The main process skip all branches and finishes. Print: Self-replicating process
This Print process now will do similarly to the other self-replicating process - its more straight forward. To just spool the files and reads the datamapper values to create Reconciliation report, MRD and any inserting requirements. Once all files are spooled. It gives back the control to the Main process to finish up.(PDFs are stored in file via Output Preset)
Back to the main process. Merges all PDF to form one archive pdf file, creates proof files for print or digital channels, merges all reports, generate a few individual pdfs , finalize and sends email notification to the operator.
The process is now complete.
All non-Connect/Workflow tasks are handled and heavily supported by an external program to do most of the data processing/crunching.
The out of memory occurs expectedly producing the PDF or reading the metadata in the “Self-replicating” processes that were used. No memory issues arose from running any external programs however long they take. Its usually really comes from Workflow/Connect specific action.
You may think that the flow could be improved or done differently. But this is a straight forward approach we took as theres more ruling to specific job some more complex than others but I left some of it out. This way we could be more flexible in each job that uses this workflow structure.
Now the task that sticks out is the metadata file loading and reading but updating/rewriting this so it uses REST Api to get data values can be mammoth task to undertake and introduce more bugs.
I would really prefer if there is under the hood that could work globally to freeup the memory when they are no longer needed. As I assumed would happen with this self-replicating processes as they seem to build up. We dont really need them to persist , once the process concludes freeup the memory it used and garbage collect for reuse I guess.
In the screenshot you shared in previous post, you have an XML splitter. I just read your whole explanation for your Workflow but don’t see that there.
XML in Workflow are notorious to become ten times larger that the original file…could it be a factor?
I am not considering this, at least not yet. Unless, and until, the flow is proven to be problematic, being inefficient is not a flaw in and of itself. And from all the work you have put into it, it doesn’t appear to be inefficient, quite the opposite in fact.
That is irrelevent. Workflow is mostly written in Delphi, with some modules in C++. Both languages are compiled to native code, not to a garbage-collected runtime such as Java or .Net. As such, memory management is deterministic. That can be both a benefit and and curse, depending on how you look at it. But the important thing in this context is that “a function which reclaims memory” doesn’t make sense. When the process ends, all memory, minus caching and overhead, should be reclaimed.
From what I understand, the overall process could be thought as two main parts. The first involves massaging the input data into a proper form using a collections of tools that you have developed. The second part takes the data and interacts with Connect Server to produce the documents. It’s the second part which experiences memory usage issues.
If that’s the case, it means that there might be a way to store the data at the half-way point, and be able to run the second part multiple times from the same data independently from the first part. This would give a way to reproduce the problem at will, without the overhead of the first part.
This was actually my initial thought and many other assumptions with Workflow, I even designed my process so that they are sectioned, each branch got a conditional script that if it picked up a “data.state.ini” file it will skip “prerun” branch (where most of data process happens), then there are “print”, “final”, “components” branch etc.
I had this idea, maybe if I could do this believing that memory is freed after a process is finished. This was my first attempt
Order of action/execution:
Drops the client file
Prerun branch (custom data process base on job spec) - drops data.state.ini into /IN folder (its own capture folder IN to retrigger proces) - change state variable to “exit”
Process checks state var “exit” → Ignores all brances exit. (This is my assumption when the process finishes it should free up memory)
Capture folder see new file - data.state.ini
Skips - prerun
Data branch - ( do generic standard data process, extractions, parsing address fields, unmailables, overseas records etc. ) - drops “print.state.ini” into IN. Process exits
Capture folder see new file - print.state.ini
Skips - prerun branch
Skips - data branch
Pre-Print branch (do Connect task to separate sheet records) - drops “print-process” into IN. Process exits.
Capture folder see new file - print-process.state.ini
Skips - prerun branch
Skips - data branch
Skips - print branch
Print-process branch - (do final Connect tasks for pdf output) - drops another state… file and so forth. Until it hits last branch.
^ This set up is under the impression of the notion of memory is freed after each pass, it still failed. Then maybe perhaps I just need to give Workflow a delay so it can “clean up” after each pass. In every branch before it exit, called a batch script to delay the placement of the state file. I could even see the log console says completed and restart again after picking up the next state file. Still failed. As you can see its really simple flow.
There are still some connect tasks I used especially in “components” branch ← but this branch is secondary process that happens after the job has all necessary outputs.
This is one evidence why I dont think its really happening unless there is an setting somewhere that we are missing?.
The second evidence is what I mentioned, when I restarted the Workflow service and run this big job. It managed to complete with no failure.To my surprise “eureka”! Then I run a small job, BAM! Out of memory!
So what is happening? And consistently I observed when I blast Workflow with Connect tasks with self-replicating processes, (I even reduced the amount of process to run in one time.) it seems to hold on to “artefacts” ← this could only be memory - because thats what the error is saying.
Or is Workflow just “resting” until its good to run again? Will this be another one of my assumption?
If this statement is true “When the process ends, all memory, minus caching and overhead, should be reclaimed.”
Then this^ set up and execution should run with no failure and the self-replicating process Im trying now should work. But its not.
Let say I convert the medatafile loading to REST Api but if what I observed is actually whats happening (memory builds up even after the process has ends) - then updating to REST Api could just be another band aid that will eventually trigger OoM failure. As more jobs get fed to Workflow.
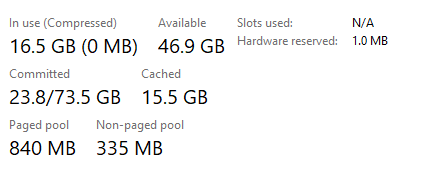
This is the RAM on our server.
From what I understand, the overall process could be thought as two main parts. The first involves massaging the input data into a proper form using a collections of tools that you have developed. The second part takes the data and interacts with Connect Server to produce the documents. It’s the second part which experiences memory usage issues.
Correct.
If that’s the case, it means that there might be a way to store the data at the half-way point, and be able to run the second part multiple times from the same data independently from the first part. This would give a way to reproduce the problem at will, without the overhead of the first part.
This sounds like what Im trying to do now. Main process starts the run, immediately exits after “passing the baton” to the self-replicating process.
Your expectation that memory should be freed between each iteration is correct. There is no need for a delay, same as there is no such thing as a “function to reclaim memory”.
It sounds like you have streamlined your process to the point where it is easy to see the problem in action.
If that is okay, I would kindly ask that you open a support ticket with your problem. Please provide all the resources needed to recreate it. A good practice is to run your process on a clean VM. If you can make it run successfully there, chances are that you have everything. Ideally you can provide a way to make the out-of-memory error occur.
Although we have policies to protect customer-provided information, you may want to anonymize sensitive data.
There might be some tasks which can be hard to port to another environement. For example, your process may retrieve data from an internal database. In this case, please mention it in your ticket description. We can usually circumvent them in some way.
I think its going to be tricky to replicate what I have workflow wise as lot of the tasks are system and network dependent.
The workflow itself needs global includes js files, then also needs UNC network drive paths, a bunch of console apps, console apps also have some library dependancy, custom internal Web API, sharepoint location etc.
The things I can think of is to make the datamapper/template as complex as possible and chunk them to small pieces and creating a report file using the outputted metadata.
Generate/Seed data file of say 100K records.
Each record is multiline data (transactional) ,a record may contain 1 or more rows in the csv file relating to the record. Each line correspond to section of the pdf document.
Datamapper contains detail tables depicting each transaction rows.
The template set up as variable overflow page. Based on detail table transactional rows
Include a graph in the template. Template to also do calculations on values to be printed.
Template to filter detail tables and comeup with values based on document rules.
Run them in workflow - Set the datamapper to output metadata so , we can generate report and page/sheets count. And another report to create MRD files.
I actually have a bunch of support tickets that pertains to this Out of Memory issue that never really got anywhere.
Tickets: 1604036,1487881
In the ticket if you got access to them should also have sample ol-template files and data.
But I think this out of memory issue pertains to how complex the job is, but then again when a big process finishes with no error. And its doing what its supposed to do reclaiming the memory. Any other jobs that runs after it shouldnt get OoM error. Which happened and have explained above.