I have a customer that regular processes big jobs, they can take up to a few hours to complete.
However there are no means to track the progress.
I am currently working on a dashboard to monitor the progress of jobs.
The Dashboard is shown on a central
For now I have used the repository to log statuses of jobs.(started, completed, total records and errors).
I was wondering if it would be possible to get the “current” record number from within the “Create content process” and push this value to the key set of the current job within the repository?
The jobs has got a GUID and this value is known within the datamapper and repostitory.
I am new to the software.
Is this possible and would this approach make sense?
FYI: There is a similar topic, but the approach to solution seems different.
Hence I created a new topic.
When using the standard Workflow tasks to issue commands to the Connect Server, you do not have access to progress information because the task itself is busy monitoring the progress of each command before returning control to the process that called it.
You could conceivably use the Connect REST API to script every single operation, but that would mean you’d have to recreate everything that each native task already does in Workflow, and that’s a pretty large project in and of itself.
Honestly, I can’t recommend tackling that kind of project. But it is ultimately your decision.
Thank you for the information.
I did something different to solve this one and thought it would be nice to share.
From within the Designer there is a control script created, that triggers a “HTML input” process within Workflow.
This customer regularly has jobs with records up to 200.000.
To prevent this trigger from happening every record, there is a small regex that prevents this and makes sure that it happens every thousand records only once.
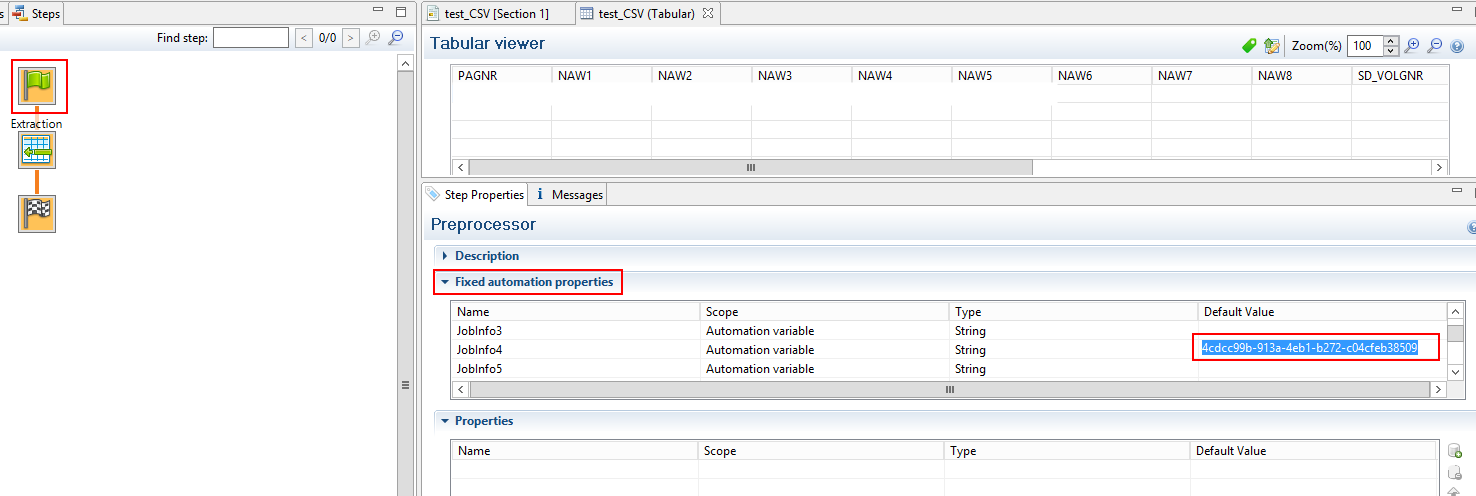
The GUID field is created (copied) from a automation job information variable.
The GUID and current record number is send with the HTML trigger.
From within workflow there is new dedicated process for this, that accepts the HTML trigger.
This process extracts the GUID and record number.
Then it updates the Repository, with this info.
FYI
I have run a few test and on a single run of 17000 records noticed a slight delay of about 10 seconds.
For this customer this is probably acceptable.
One question
During my tests it seemed that is seemed to be impossible to use a “automation jobinfo var” directly in my control script (In my case %4 is the GUID number).
I had to set this value to an field and use this in my script.
This means extra adjustments within each document process.
Is this a known constraint/bug? Or am I doing something wrong?
(I used this command “var GUID = automation.jobInfos.JobInfo4;”, which is autocompleted).
Well that’s a very clever way of doing things. As long as there is not too much latency when issuing the HTTP requests to Workflow, then it should work fine without causing too much delay in the production run.
As for automation,jobInfos, you can use them automatically at run time. However, you can’t use them at design time in the Designer because their value is only available when the template is called through Workflow’s Content Creation tasks.
I usually do something like this in my Control Script:
var GUID = (automation.jobInfos.JobInfo4) ? automation.jobInfos.JobInfo4 : "some default value";
This makes sure you get a default value at design time, and the proper value at run time.
The customer has another process that also uses HTTP input. I have changed the input to Nodjs (for a more dedicated input type) and added a response file.
During my testing the latency is about 1 second for each time the javascript kicks off a process.
For the big job of 200000 records this would mean an additional 200 seconds.
Now luck on the control script as of yet.
If I use the suggestion. The default value is always used.
Strange:
If I Extract the jobinformation within the datamapper and allocate it to a field (like automation.jobInfo.JobInfo4;)
It works fine, but when I try to use the jobinformation within the designer the value remains blank (or default when I hardcode it like the example).
Another thing I have noticed is that when I put in a default value in the Preprocessor step. I am also not able to use this value within the control script of the designer.
It seems to me that the job info variables are lost between the datamapper step and the designer step.
I am using 2019.1, the customer is still on 2018.
I will try and see if this symptom is the same in their environment.
I can assure you that the JobInfos are available in the Designer, just like they are in the DataMapper, as many of our online demos rely heavily on that feature.
However, I just remembered that there is a discrepancy between the syntax used in the DataMapper and the Designer, which is what may be throwing you off:
DataMapper syntax automation.jobInfo.JobInfo4
Designer Syntax automation.jobInfos.JobInfo4
As you can see, Designer uses the plural form jobInfos whereas the DataMapper uses the singular form jobInfo.
Also, note that the Designer does not use the DataMapper’s pre-processor step. That step is only effective when running the DataMapper operation.
This is an amazing “hack”, and I’m shamelessly stealing it.
Did anyone manage to resolve the issue with JobInfo variables not transporting their values into the Template?
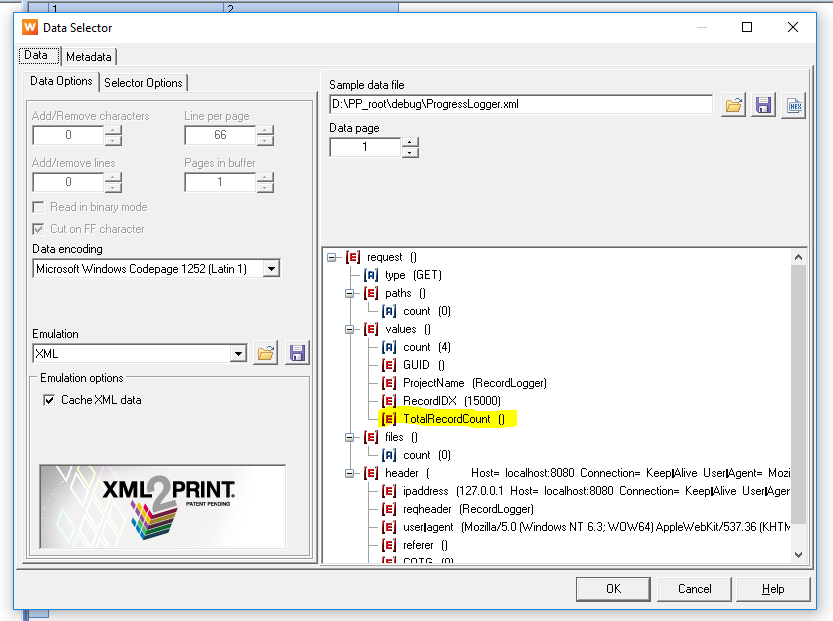
I want to display/log “record X of Y”, not just the current record.index. So in Workflow, after doing Execute Data Mapping, I put the “Datapages in Job” value from Metadata into jobinfo9.
In my Control Script, I try to reference JobInfo9 but the value is always blank.
var counterHTML;
var recordIDX;
var GUID = "";
var ProjectName;
var TotalRecordCount;
recordIDX = record.index;
recordIDX = recordIDX.toString();
ProjectName = record.fields.ProjectName;
TotalRecordCount = automation.jobInfos.JobInfo9;
if(recordIDX.match(/.*(?=000$)/))
{
GUID = record.fields.GUID;
counterHMTL = loadhtml("http://localhost:8080/RecordLogger?GUID="+GUID+
"&RecordIDX="+recordIDX+
"&ProjectName="+ProjectName+
"&TotalRecordCount="+TotalRecordCount);
}
@Phil,
That explains it. Thank you.
FYI
I have added a small bit to the script, so it would also trigger after only 10 records (to see that the processing is begun).
My full script is:
var counterHTML, recordIndx, GUID = “”;
recordIndx = record.index;
recordIndx = recordIndx.toString();
if(recordIndx.match(/^(10)$/gm)){
GUID = record.fields.GUID;
counterHTML = loadhtml("http://localhost:9090/count_page?GUID="+GUID+"&recordIndx="+recordIndx);
}
if(recordIndx.match(/.*(?=000$)/)){ //Matches with every record index that begins with 000. Triggers only with "thousand numbers"
GUID = record.fields.GUID;
counterHTML = loadhtml("http://localhost:9090/count_page?GUID="+GUID+"&recordIndx="+recordIndx);
}
I have one question remaining:
Today I tried to implement this solution at the customer, but it fails on the loadhtml() function.
I also tried to create a remote rhtml snippet and call it with the loadhtml() function. Same issue.
Also when I try to retrieve another webpage.
It does not even trigger the process.
It gives the error “MalformedURLException”. As mentioned the customer is using a older version PReS connect (then my test setup).
Is this a known bug/restriction of 2018.1?
and would a upgrade fix it?
Ah. As a feature request, then, I would request that the “Set Job Infos and Variables” plugin in Workflow be made “Connect-aware”, so that, AFTER the Execute Data Mapping plugin, but before the Create Print Content, any changes to Job Infos and Workflow Variables made by the Set Job Infos… plugin be available within ALL contexts of the Template.
Thanks.
P.S.
Following up on your suggestion to use the ExtraData field. In my specific case of wanting the print template to be aware of the total record count, this would require:
In the Execute Data Mapping step, make sure to export all values into metadata. This takes much longer.
Metadata Fields Management to push the total record count into the Document _vgr_fld_ExtraData field, an extra step taking a good amount of time.
Update Records, which pushes ALL of the metadata back into the Connect database. Essentially re-doing the Data Mapping, this time from the metadata source.
That’s a massive amount of overhead to get a single value (total record count) from Workflow back into the print section.
Works like a charm, without much overhead (I think).
The only downside I can think of is, that you have to recreate this setup in every process (Which you want to monitor).
Instead of only importing the script.
You could use a single process to monitor several operations. You would simply have to pass an additional parameter (e.g. the “name” of the operation to monitor) and you would store that as well in the repository. Then you can filter the repository values according on the operation’s name.
That works if the variables are defined outside of Connect plugins. In my specific case, the value I want is only available after the Execute Data Mapping (the total record count), so it’s not available in the Data Mapper.
That is true, We solved this by running a dedicated datamapper for counting the line numbers. Our input data is CSV.
We would import it as one record within datamapper, count the lines and write it to a local file (with GUID for a name).
@bob2b,
Instead of running a dedicated data mapping process just to count the records, you should execute your specific data mapping process, making sure to specify the Validate only option. This will not only validate the entire job without actually extracting anything, but it will also give you the total number of records the DataMapper will be extracting when you run it for real.
Thank you. That is a better and much simpler option.
I will try that in the future (for now the work ends with this customer).
Just for feedback.
Setting the mime options and delivering a valid HTML, did not solve it for this customer.
But I have advised the customer to wait for the release of 2019.2 and then update it, because I know that it works with 2019.1 (and probably higher as well ).
As a bonus, we should be able to use the error messages a little better with 2019.2 and project these on the website.
Whenever I run the “Validate Only” option, I get a “Index cannot be negative” error message, and no metadata is generated. Any insight, or should I open a ticket?
Regarding “knowing the total record count within the Print Context”, I only needed that in order to pass the current record index AND the total record count back to the HTTP process in the Control Script. Bob’s comments led me to the alternative, which is to store the total record count in the Data Repository with a unique key (GUID), all in the Workflow. The HTTP “progress logging” process just needs the GUID and the record.index, as the total will already be there. Much better than using ExtraData.
I get the same result. In my case I have a preprocessor script that changes the data layout to allow easier table looping. In this script I have a try/catch that forces an error when a condition is met. However I get the above error which also states that metadata could not be created.
@Sharne: well if you purposely generate an error inside the pre-processing step, then it’s kind of normal that the Validate Only option would fail because it’s unable to even get to the first record in the file.
However, if the Validate Only option outputs an error message and you are not using a pre-processor - and this comment applies to @TDGreer as well - then you should definitely open a ticket because that’s not supposed to happen.