I’m very new to OL Connect Designer and need to create a print template with data from a text file that looks like this:
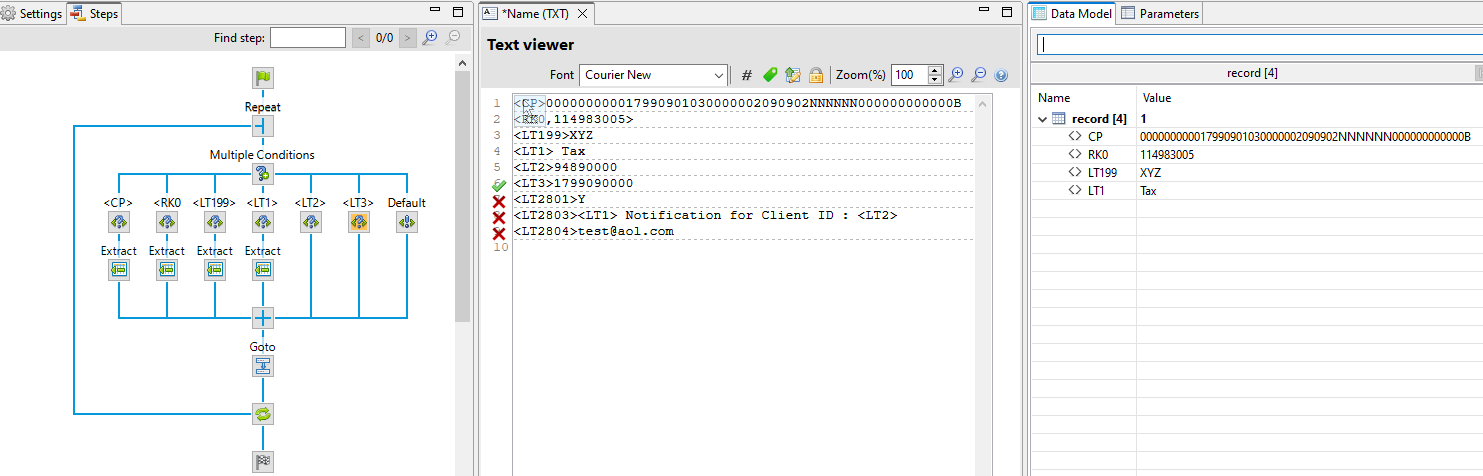
<CP>000000000017990901030000002090902NNNNNN000000000000B
<RK0,114983005>
<LT199>
<LT1> Tax
<LT2>94890000
<LT3>1799090000
<LT2801>Y
<LT2803><LT1> Notification for Client ID : <LT2>
<LT2804>test@aol.com
The fields won’t be based on location so I’m assuming the only other way to extract them will be with a javascript. So my question is, what would be the script that extracts the value after “< LT1 >” and before the following “<” on the next line, as an example, that I could then apply to all the < LT > tags to extract the data that follows them.
The < CP > tag is the start of a new record, and this is just a very small sample of all the possible tags so I want to make sure I am doing it correctly before mapping them all.
If there is a better way of mapping this type of data then I’m all ears as well!
Hello @Laura2795,
First of all, welcome to the OL Forum communicaty!
As for the question asked; splitting the data into records based on the <CP>-tag shouldn’t be difficult but in case the tags existing on the following lines can basically be placed anywhere in any order will make it difficult to extract this data.
Thanks Marten 
I figured out how to switch between the records using the CP tag, but yes the rest of the tags position in the data won’t always be the same or some won’t be in the data at all.
Would I be able to base the fields off JavaScript instead of position to extract the values? I thought it might work to extract everything after a tag but before the following tag?
But again, very new to this so have no idea what that script would be, or if that’s even possible!
Hi,
Doing my usual morning reading. Just curious as to why a multiple conditions step is out of the question? (Might need more than one if you want to target exact values like <LT1> versus <LT199> or <LT2083>)
Hard to tell if this is viable without seeing the data, just a thought.
Regards,
S
Hi @Laura2795,
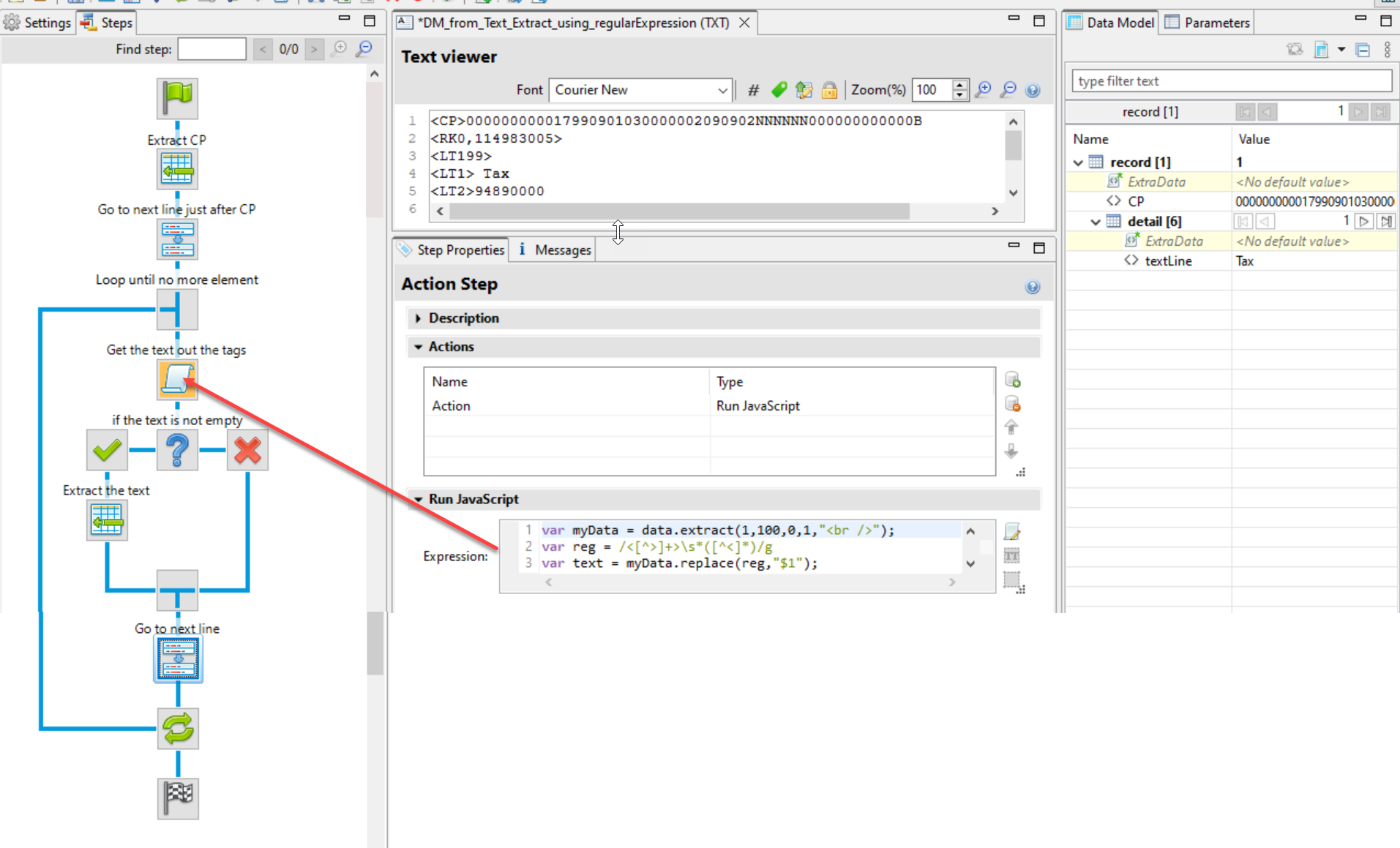
If you know the regular expressions, you can use it in a script to extract the text between tags.
This regular expression /<[^>]+>\s*([^<]*)/g works on your example above. Use it in an action step based on Javascript as below:
// Supposed max characters in a single line is 100
var myData = data.extract(1,100,0,1,"<br />");
var reg = /<[^>]+>\s*([^<]*)/g
var text = myData.replace(reg,"$1");
The steps flow looks like the image below:
I attached the Data mapping configuration from your text data example. It is a suggestion to text data you provided. A solution will be based on your data and also template. This is a suggestion may be can help you to handle your text data.
DM_from_Text_Extract_using_regularExpression.OL-datamapper (4.1 KB)