Hi,
I have a simple workflow that accepts a delimited data file, goes through the data mapper and content creation then lastly output.
Now I would like to be able to split the pdf based on several rules and in order.
- if address field is blank - goes to “unmailable.pdf”
- if last name contains - “Smith” goes to “smith.pdf”
- the rest would be divided to records with number of pages and goes to 1-2.pdf and 3plus.pdf
Is this achievable?
Thank you.
Regards,
E
Since you just have the 3 conditions, seemingly, I’d probably use a combination of Set Properties and Retrieve Items to perform the initial separations in the Workflow.
So you’d start with something like this:
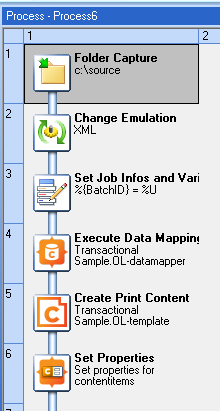
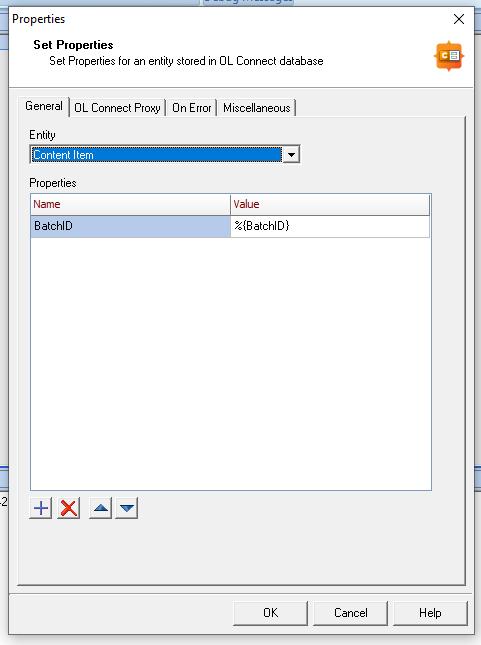
We start by setting a BatchID using %U. This ensures that in the following steps we’re getting records from this job and only this job. Then we run the Datamapping and Create Print Content as normal. Lastly, we use Set Properties to tag each Content Item with that BatchID
From here we’ll branch, retrieve a subset, and then finish processing with a Job Preset and Output Preset.
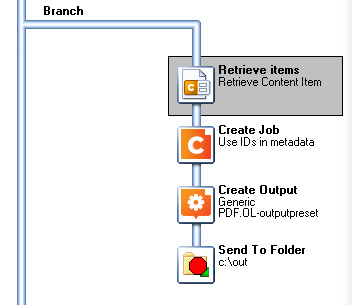
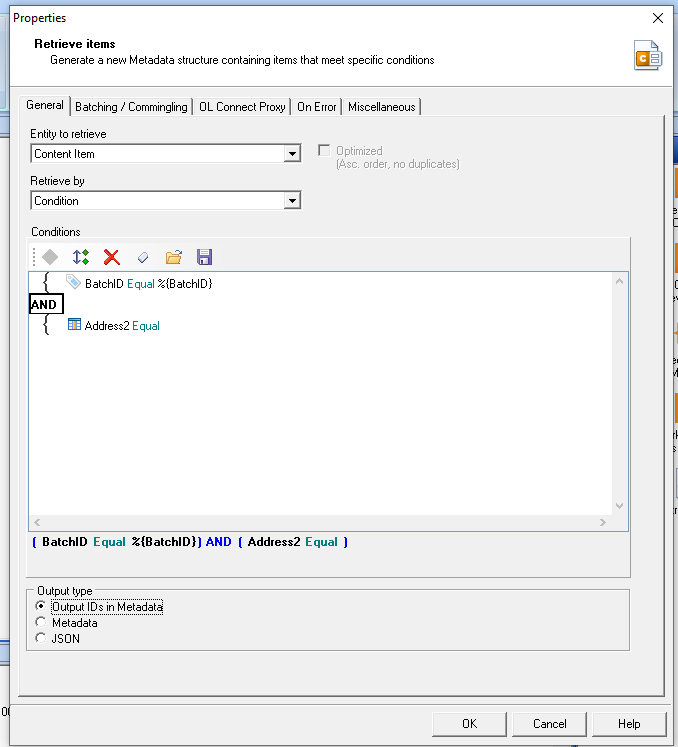
That Retrieve Items then looks something like this, where we retrieve Content Items by the BatchID and our other condition. In this case, if Address2 is empty:
This whole branch may then be repeated with a different Retrieve Items without the need of re-running the Datamapper and Content Creation. They’re already stored. So getting everyone who’s last name is Smith from that set is just another query, just as is getting everyone who is NOT a Smith and address is NOT empty
On this last set, you’d likely want to get into different job presets and output presets to allow you to perform the Size Grouping separation you’re after
I have not thought about using Retrieve Items this way. I will definitely give this a try.
Lastly, can you give us insight about Retrieve Items task, specifically when you retrieve content items/record ids from a previous process for example, what are you actually getting?
When a previous job ran and saved the content item ids in a file, then later on when I retrieve the items to generate the pdf, and followed by job/output preset, it was complaining that it didnt have content set id to continue , so I provided the ID. Following that I decided to use metadata filter to only return set of records I want then applied metadata sort so that it was ordered based on a field.
And Im assuming that I will get the intended output, the pdf output I gotten was for the whole unfiltered/unordered sets which was the original.
After a lot of going back and forth, that I decided I may have misunderstand how it works. Basically I just really like to understand how Retrieve Items works.
And thank you and appreciate the detailed input above.
Cheers
E
Just an update:
I tried this set up and Im getting an error and complaining about an invalid Content Set Item collection.
Sorry for the late reply. Without seeing the full configuration, this would be hard to troubleshoot. If you’re still having trouble getting this to work, feel free to open a ticket and the Support team can remote in with you to look over what you’re doing. It could be as simple as the filter in your Retrieve step not finding anything.