Hi Folks
I have a file in plain text format where I extract by location on each line of this file.
In this file there is an identification code for each municipality, but there is no address, no municipality name and no sub-item number.
The logic would be as follows:
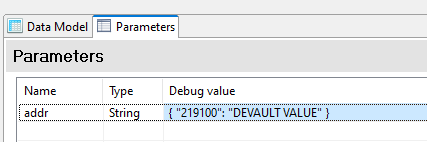
When Datamapper extracts the code on the line, we create the “addsAlt” field where the list of addresses for that code has been added.
On the next line there is another different code that will change the address in the “addsAlt” field
Another field has been created with the name “nameAlt” where the names of the municipalities have been added.
Is there any way of creating another TXT, CSV or even JSON file with this information and adding the new addresses to this file so that we can abandon the routine of opening the Datamapper file to change or add other addresses?
This case is for my needs, but it could have an effect on the needs of another case study, such as Fruits.
Each fruit product has its own EAN code and when Datamapper extracts this EAN, the other fields will ‘tie in’ with the respective fruit name and description, hypothetically.
Feel free to propose alternatives for the same case.
BR