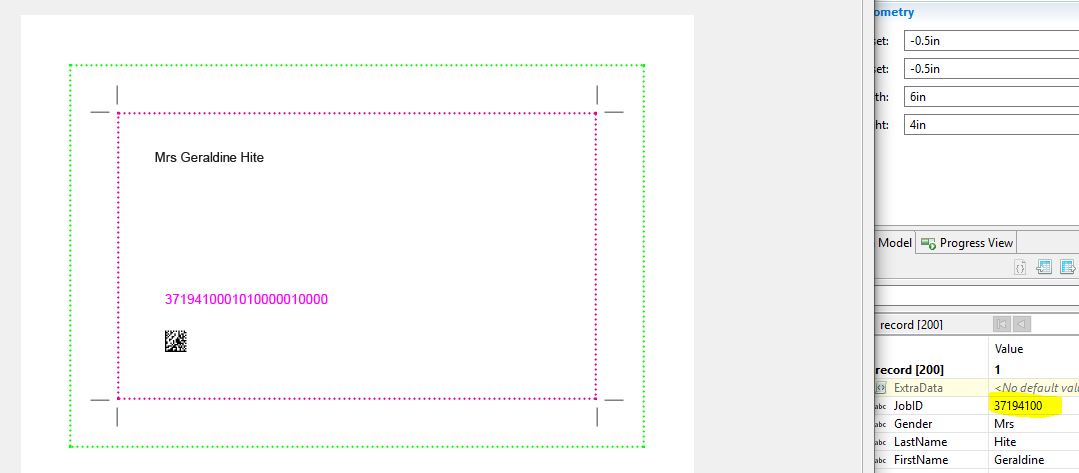
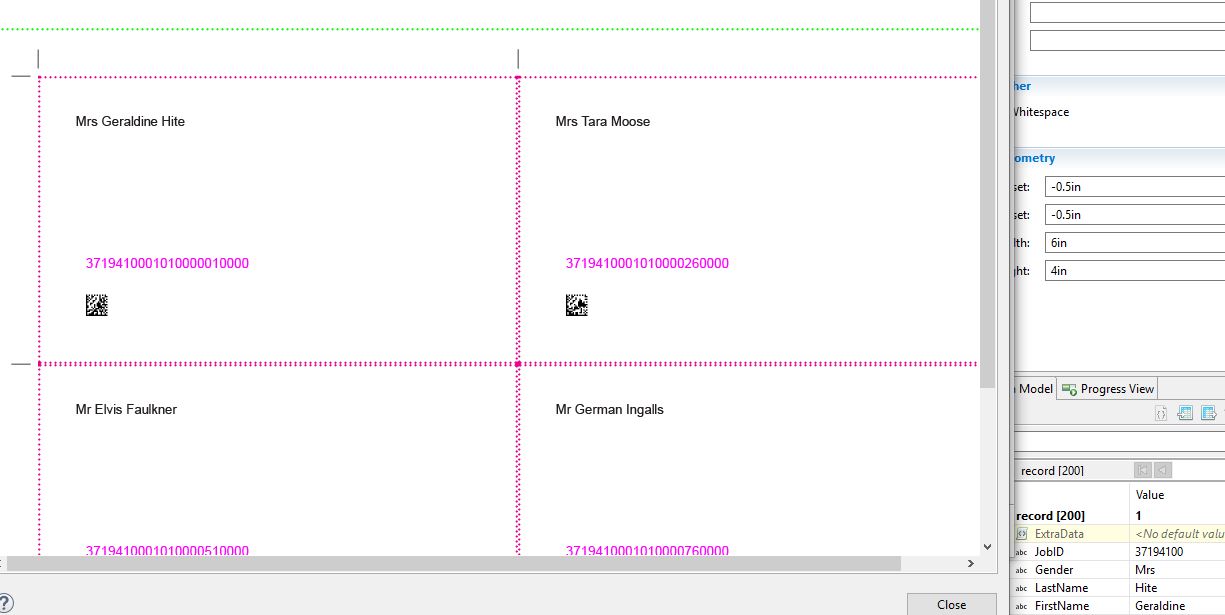
You’re correct in your description of the Document level. It is pre-defined as the ensemble of pages relating to a single record. However, document.nr would give you the document number within the Document Set. If no other user defined groups have been defined, then the Document Set will contain all of the documents generated from your data set and the number would increment once per document.
If you want the page or sheet number within the document itself, you need to use page.nr (page.sequence.document) or sheet.nr (sheet.sequence.document) respectively. Similarly, if you want the total page or sheet count within a document, you’d use document.count.pages or document.count.sheets respectively.
There’s an invaluable reference for all of these here: Variables available in the Output
User Defined Groups
These groups are all defined in the Job Creation Preset. If left undefined, there will be one of each comprising the entire set of data. These consist of
Job
Job Segment
Document Set
Your primary goal with these would be to group up your data into logical separations. For instance, assume you had a mailing destined for recipients in both Canada and the United States. You might begin by grouping by Country at the Job level in order to separate the US and CA recipients.
Now assume you are incentivized by your respective mailing agencies to further sort the mailpieces. You might choose to group by State/Province at the Job Segment level. Then, most likely, you’d want to group up by individual postal codes at the Document Set level.
So everything is grouped up now. What can we do with this? Well, one thing would be to actually split up the output. If we were to choose to separate on the Job level at this point and print to PDF, we’d get two PDF files. One for the US and one for Canada.
Similarly, if we were to choose to split at the Job Segment level, we’d expect a fair few more files on output.
Metadata and Output
So now we have a pile of files that are likely largely unidentifiable. We need to get them named according to their State/Province. Now we’ll invoke some metadata. Given that we’ve just split this at the Job Segment level, we need to also define our metadata at that level in the Job Creation Preset as the separation level is the only level accessible to the Output Mask
${segment.metadata.State}_${template}
Therefore gives us names such as
AB_TemplateName_0001.pdf
AZ_TemplateName_0011.pdf
BC_TemplateName_0002.pdf
If I wanted to add more information to the filename (country, zip, or other) these fields all must be added to the Job Segment level here. You can add as many as you like.
${segment.metadata.Country}_${segment.metadata.State}_${template}
Similarly, you can use the Output Variables in the name or on the page by way of Add Additional Content. You just need to be sure to respect your separation levels.
For instance:
${segment.metadata.Country}_${segment.metadata.State}_${segment.count.sheets}_${template}
This inserts the total number of sheets generated by each of our separation options. Giving us name such as these
CA_AB_2_TemplateName_0001
CA_BC_4_TemplateName_0002
CA_MB_2_TemplateName_0003
On the other hand:
${segment.metadata.Country}_${segment.metadata.State}_${document.count.pages}_${template}
This results in an error. We’re asking it to split at the job segment, but to insert the page count for the document in the name. Well… which document? Each split file potentially contains multiple documents.
In such a case, the only place we could realistically use document.count.pages would be on the print page by way of Add Addtional Content.