Hi,
Why do I keep getting this error?
Basically all I want to split my pdf based on record/document count.
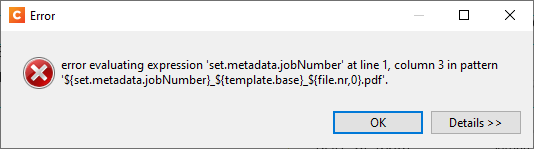
Here is my set up:
Job Creation
Output mask
Output Creation
Proof print summary
if anyone can pinpoint my mistake here, would be much appreciated.
Thank you
E
It looks like when you set your separation option to “Separate by Count”, you lose all metadata field access which is unfortunate.
Only work around I can think of is, if you are using this in a workflow, is to output the pdf to a temp folder and pick the pdf and rename it.
Alternatively, you could create a new field in Datamapper, in which you enter a number by script. This number is incremented by one every 100 records.
In the output you can then do a grouping and separation based on this field (instead of exact separation you choose separation on document set level).
That should work, though I haven’t tested it myself yet.


