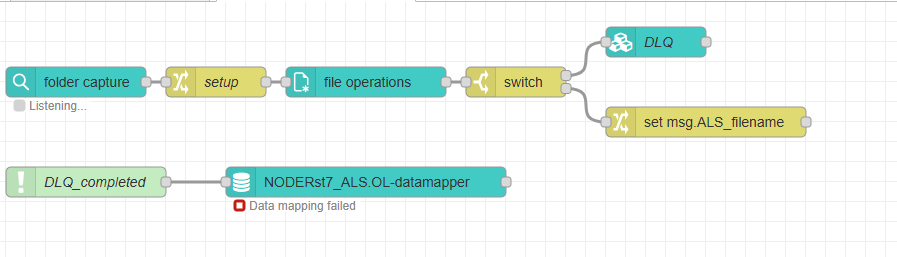
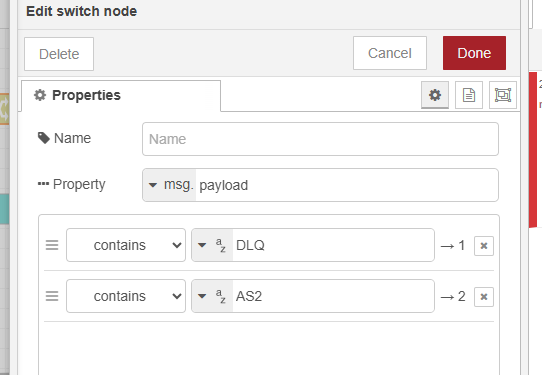
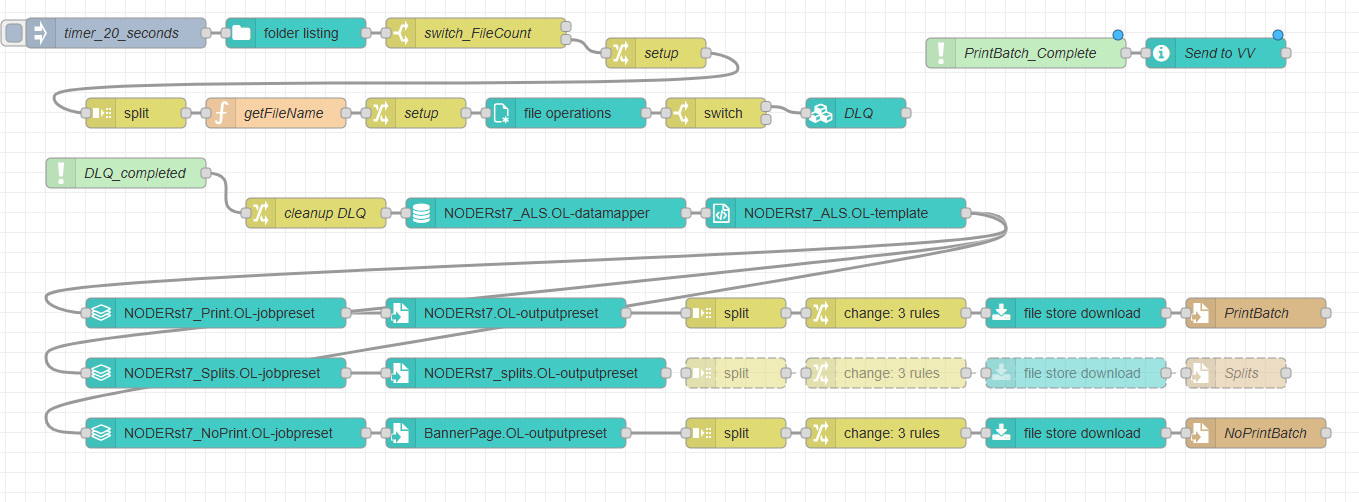
I pick up two files, and archive them. I process the first file with an “all in one”, and that succeeds. When I process the second file, the datamapper tries to process the FIRST file again, and so fails.
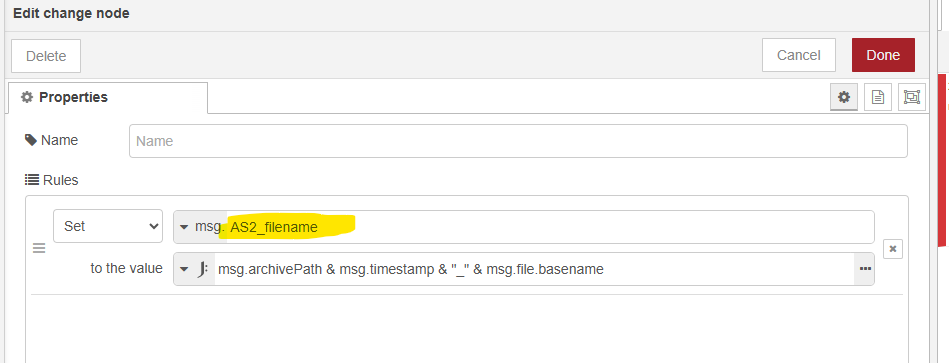
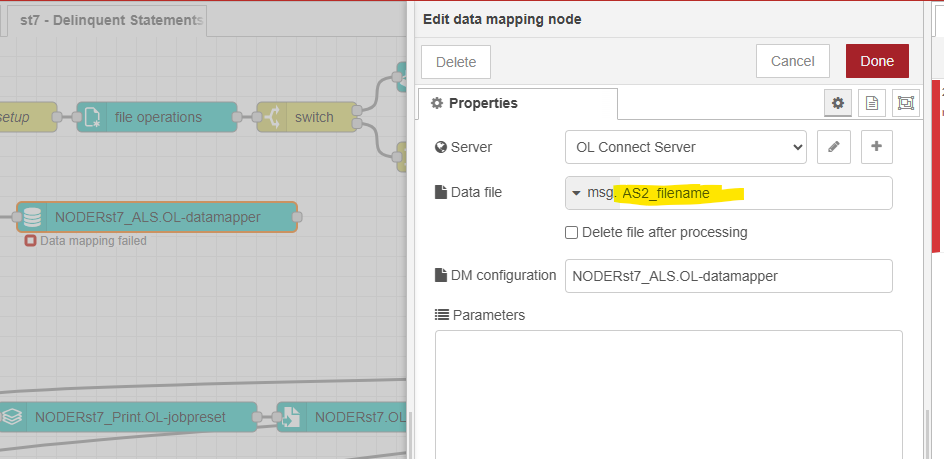
The data mapping error is because the data mapping node is trying to process the original file even though I’ve set it to use a different file “msg.AS2_filename”.
If I remove the “switch” entirely, and set the name of both data files in the first “setup” change node, the same issue occurs. Really, no matter how or where or when I set the data file path and name for the 2nd data mapper, it always processes the first file and so errors out.
The only exception is if I wire the 2nd data mapper directly to the second output of the switch. I’ve done this to prove that my settings are correct. I can’t do that (in production) because they’ll both process asynchronously, and I need the DLQ output completed before I can run the 2nd template.
I’ve also tried wiring the 2nd (ALS) data mapper to the 2nd output of the switch node, followed by a Set Properties. On COMPLETE of the Set Properties, I do a “query” to retrieve my data set, but it always comes back empty.
But If I wire the “query” directly after the “set properties”, it works.
Something about un-wiring the nodes and putting some behind a “complete” node breaks the data mapper, query node, etc.
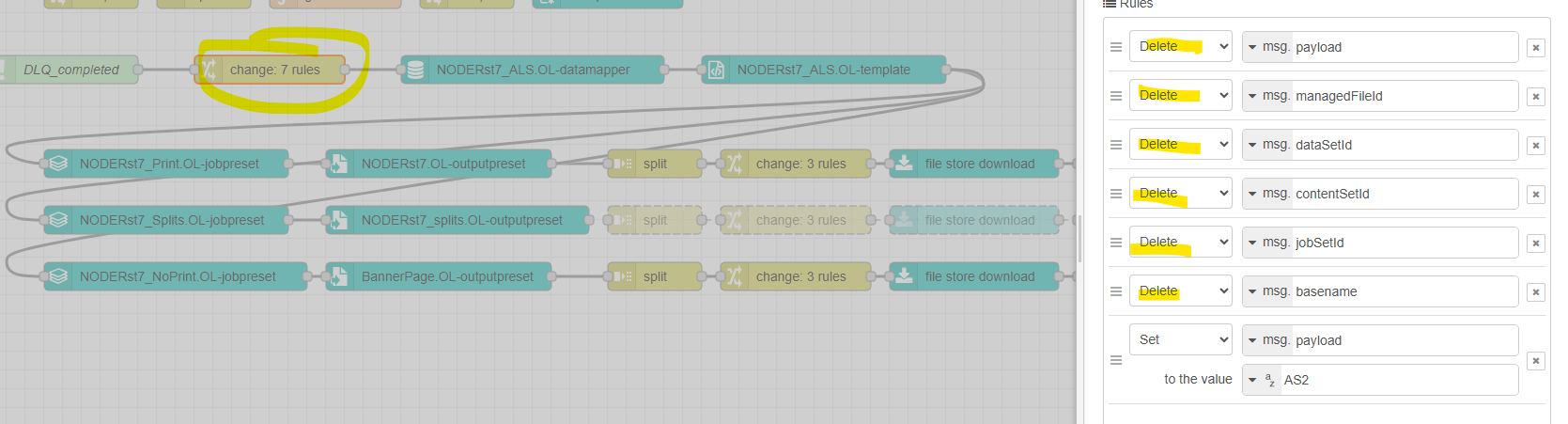
I finally have this working. After MUCH debugging, I realized that no matter what value I put in the “Data file” field of the Data Mapper node, it would be IGNORED if there was a msg.managedFileId field. Since the “DLQ” branch of my switch performed an all-in-one task, it created .dataSetId, .managedFieldId, etc. and, upon the “complete”, those values were being used by my “AS2” datamapper instead of the value in the “Data file” field.
My fix to force the data mapping node to use the file I specified, is to precede it with a “change” node to delete all of those fields.
Not sure I agree with this one. To me, the GUI values are kind of like a “default setting”, which can be overridden by setting the corresponding msg/payload properties. If it were the other way around, then overriding those settings would be more complex.
That said, I think the node could offer an Ignore managedFileId tick box that would allow both methods to be used. The same option could also be made available in other nodes that have the same behavior.
I’d like to rewind a bit and go back to the original post to better understand the goal of the flow. This will help me grasp the scenario better and come up with a recipe.
From what I gather, the steps needed are:
Create a backup of the incoming files.
Output individual files for archiving (File A).
Output a single file for printing.
Output a single file for records that should not be printed.
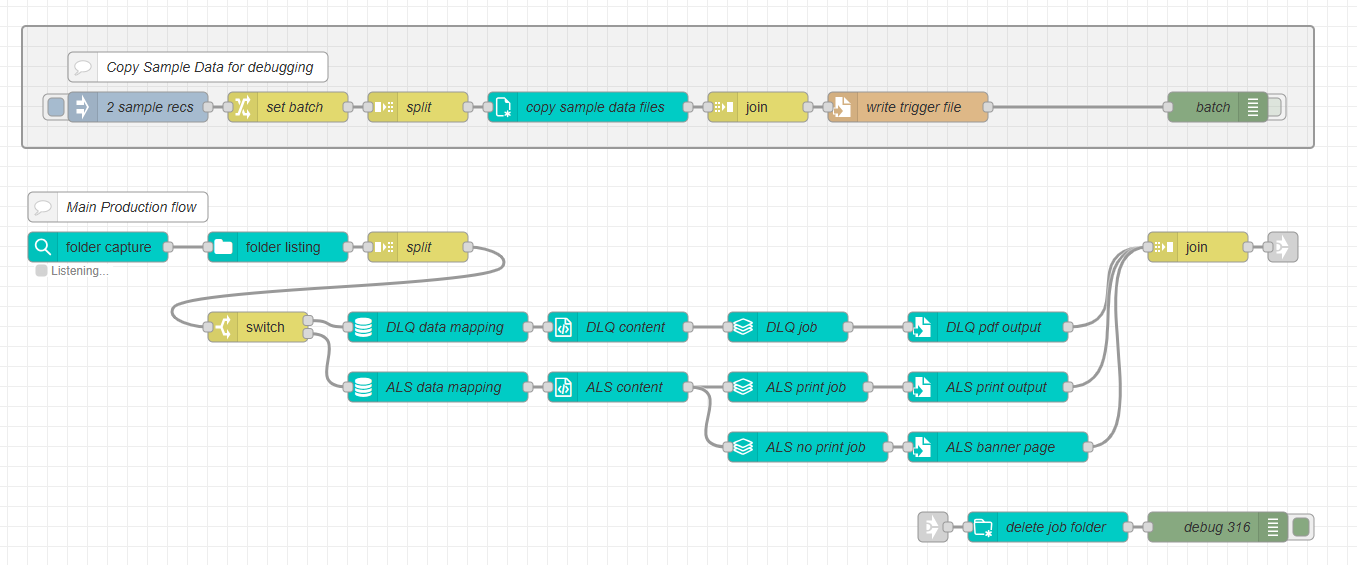
Are the two files arriving at the same time? If so, could they be saved in a unique job folder in the hotfolder, and then create a .trigger file once both are saved? If this is possible you could watch the hotfolder for .trigger files, then perform a folder listing to treat the files as one job.
With this approach, you can use the split and join nodes, as shown in the image below. The folder listing will gather the job folder contents as an array of file paths, and the split/join will loop through them. After it’s done, the process continues after the join node, where I clean up the job folder.
Think “commingling” but without actual commingling.
Yes, there are two files, a Statement data file (the DLLAS2_ALL.csv), and a Delinquency Letter data file (DLLDLQ_ALL.csv).
There is a set of Connect Resources (data map, template, presets) per data file.
The Statement Template uses a Dynamic Background Script to ingest the output from the Letter Template.
The job must:
Archive the data files (and I’ll add, using the same “timestamp” value in the archived filename. My initial flow as posted, with a “folder capture” capturing both files, caused the “setup” change node to run twice creating two slightly different timestamp values. I’ve fixed this by starting with an Ingest node followed by a Folder Listing node.)
Run the Delinquency Letter first, and upon completion, run the Statement template. The Statement template requires the output from the DLQ Letter.
Produce three output streams:
a. output statements for print and mailing
b. output statements for customers opted-out of physical mailing
c. separated output of all statements, 1 PDF per statement
The next part is to empty the “FilesStage” folder, which is where the DLQ Letter PDFs are produced. I tried a Folder Operations to Remove that folder, followed by a Folder Operations to Create that folder. The “Create” is failing, even though I’m using the same variable, that value is altered and the folder is created with the wrong name in the wrong place. I’m looking into that now.
I’m afraid I have to contradict this. In general in Node-RED, when you use the node UI, those settings override whatever may be passed along in the msg properties. In recent nodes this is often made much more explicit.
One way to make this explicit is by having a dropdown where you can choose to use the variable msg input, or a specific other option (for example, the ‘Output format’ in the ‘email content’ node.
Another way is by using a typed input field in the node UI, where you select either a specific msg property, or a text string, or some other variable.
The msg.managedFileId property is truly a special case, as the datamapper node is explicitly set to prefer any value that comes in from that property.
I saw your post, and also some related posts asking a similar question. So far it seems the consensus is that UI values should take precedence over payload.
Seems like it but then again, they also state that it is up to the developper. I guess note should be added to the doc of each of our OL Node. I will raise the issue with our R&D and Product Manager.