Can I retain a field from one record and add that field to the next record with DataMapper?
We receive utility bill mailings in PDF forma, and I have been using DataMapper to extract address data into a CSV file for Presort, and using an Output Preset to split the PDF into individual statements/pages.
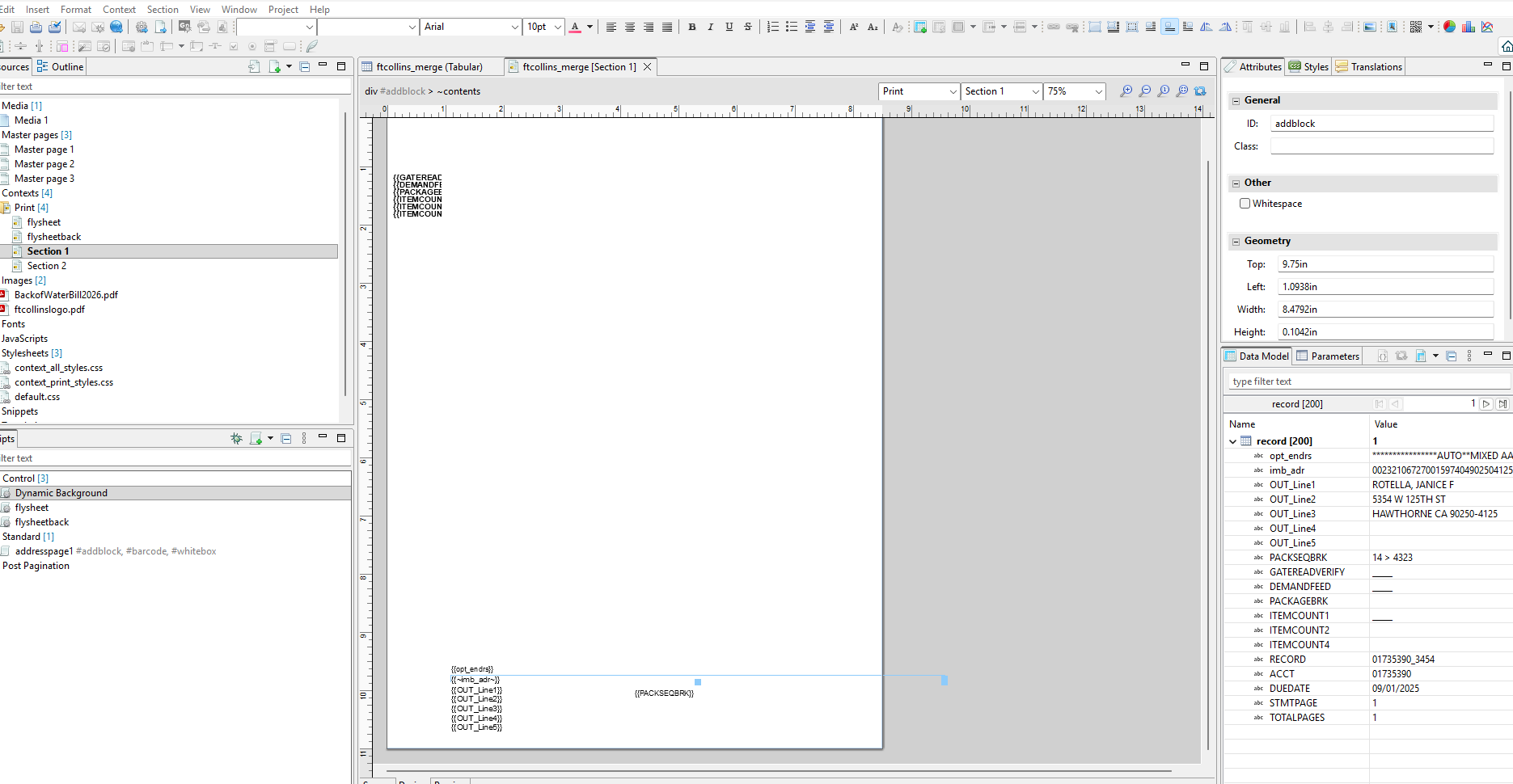
I am splitting the current mailing by pages, since many statements have multiple, unique pages, but pages following the first do not have the account number on them. I need that field to ensure the multiple pages are combined into the same mailpiece when I stitch the PDF back together.
Is there a way to add the account number field to pages 2 and 3 of a statement, and then replace the value once a new page 1 is reached?
It is not possible to copy a field value from one record to another. This is only possible when both fields are in the same record, by using the set(record) method.
This is unexpected and unfortunate. In PP7 it was a simple thing to write a value to a global variable, and retain that value until a new Page 1 was reached. I was sure something similar could be achieved using JavaScript. Perhaps in template design, but not Datamapper?
I am going to have to re-think this whole process.
Yes, I will have to split by document, which I have done for single page statements (or 2 pages, front and back). This job has a small number of bills that contain a third page.
I have to account for multiple pages during the Presort process, and add OMR marks to subsequent pages in each document when stitching the PDF back together for printing. Statements with duplicate addresses are also combined during presort, further complicating the computation of total pages/sheets in each mailpiece.
Using the account number AND page number as a unique filename for each PDF page (record.fields.acct+“" +record.fields.pages+"”+record.index.pdf) also ensured each page was a separate record in the CSV file, to which OMR fields could be appended. Now I have to add data fields to pages that don’t exist.
I am sure this is a solvable problem. Some conditional logic and scripting will certainly be able to distribute record data over multiple pages. I am sure this forum will continue to be essential to this end.
After Presorting, data is output in presorted order as a CSV file, and a second Datamapper and template are created to place updated address data and OMRs on the page.
A Job and Output Preset write the newly reconstructed PDF file for printing.
I hope this is clear enough.
I was pretty impressed with myself for figuring this out (with LOTS of help from this forum). After nearly 15 years doing everything with PP7, Connect has been quite a different beast, I have really only used Connect in this context of presorting address data from a PDF data source, as more and more of our clients convert their output to PDF.
I have a method that carries the value from the previous record that might help. After your field extractions you will need to add an Action step with my code (You will need to edit the code to match your field names).
Although you method has merit, it still rely on a false assumption: the Datamapper threat all records as a single thread.
The Datamapper engine, when going through a job, will split it into multiple threads, each handling its batch but NOT speaking with each other, meaning that whatever value you wish to convey, one thread cannot pass it to the next.
It could work for you at some point as how the splitting is done is beyond my knowledge and granted that it could work from within a thread, you’ll end-up at some point with that value being lost.
The only sure way this method could work would be to add an option forcing a single thread to be used by the Datamapper engine. Of course the result would be a lost of speed.
Thank you for the suggestions, and I will explore @Sharne’s solution soon.
But I have proceeded with this job by simply splitting the source PDF by page. Record.index now refers to every individual page of the PDF (1.pdf, 2.pdf, etc.), and is now a field included in every record of the .CSV file.
Some simple scripting in Redpoint DM ensures the pages for each statement are grouped together, AND each page is now a CSV record which OMR marks can be appended to.
I would prefer each split PDF filename was a little more descriptive, but after some testing, this method has done the job.