in many processes I have different approaches to reduce the range of records used for a Connect template. In same cases I reduce the input file, in others I store the record informations in the repository and only fetch what is needed, sometimes I use a filter to select the desired records and so on…
Dependend on the data and the requirements it makes sense to use different ways to get the best/most performant result.
But I often have the following challange:
I get a data file (csv, xml or pdf) containing an unspecified number of records. The data file should be processed in the Connect Datamapper to create a data model for a Connect Designer template (easy standard procedure).
Often customers want to have two separate outputs in one automation process. In the first step they need a pdf file based on records 1 to 5. In the second step they want to create an output file based on all records.
What is the easiest way to set the record range in an automated Connect processing?
I looked for a non coding way to do this for proofing. So all my Workflow processes generate normal output using the entire database. I then generate 50 samples to generate a proofing PDF that is sent off to the client for approval.
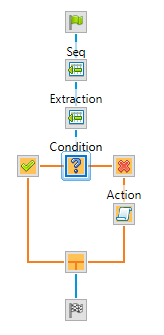
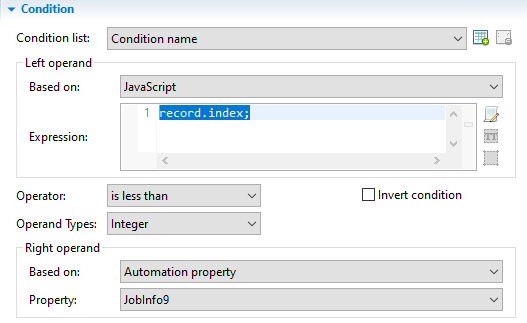
Here is one using CSV data. Extract all your fields and once done add a condition based on JavaScript using record.index; as the expression. Operator set to “is less than”, Operand type set to Integer. Based on Automation property, Property JobInfo9.
The steps for a simple CSV:
Condition settings:
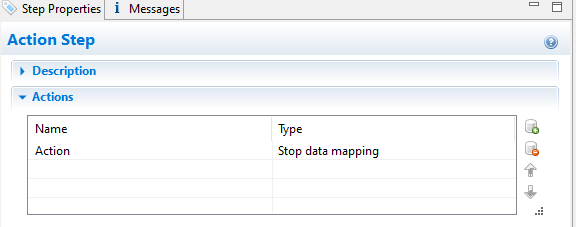
In the false branch I use a Action step set like below:
With this method you would need to run the data mapper more than once in Workflow. Use a Set job Infos and Variables before your data mapper and set JobInfo 9 to the number of records you want to output. So in your example you would set Jobinfo9 to 6 so the condition in the mapper outputs less than 6 records.
Perhaps there is a more eloquent way. I’m stuck in Connect 2021.1 until we update soon.
thank you for sharing your solution. In this case I have to create two separate DataMapper configurations.
Or better I could use another condition based on another jobinfo with value “print” or “proof”. So I only have to maintain one configuration instead of two.
In JavaScript words:
if(Jobinfo8 == "proof"){
if(record.index < parseInt(Jobinfo9)){
extract data (only record range)
}
else {
stop datamapping
}
}
else {
extract data (all records)
}
I like that approach and think about recommending it.
But maybe there is an even easier way with better performance than twice executing a DataMapper configuration in the Workflow process?
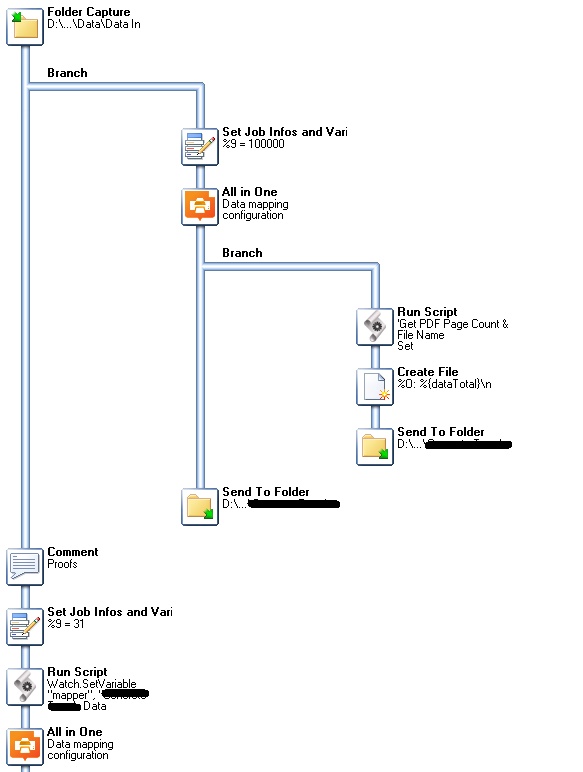
My attempt was to process all records in one DataMapper step and then reducing the metadata (Datamapper output) in a branch (metadata filter). That works but I don’t like that I first have to add an additional field to the Workflow metadata (index number per document). Otherwise I can not set a condition in the metadata filter plugin.
Only need one data mapper and one Workflow process. In the below pic I set %9 to 100000 because I know the data for that job will never reach that number, so all records are processed in the first branch. Underneath that is the Proofs branch where I set %9 to 31 so that my proofs file/pdf is only 30 records.
But maybe there is an even easier way with better performance than twice executing a DataMapper configuration in the Workflow process?
I went this route years ago and it is fine for my needs. Is there a better more efficient way in Connect 2023 is beyond my scope as mentioned I’m on 2021.1. Perhaps one of the OL staff here can advise a better solution.
You could improve slightly on it by also passing a starting record index (for instance, you could store a JSON string in the parameters that Workflow passes to the DataMapper: {"start":10,"end:20} ), and then your data mapping configuration could use a combination of the “Skip to next record” and “Stop data mapping” actions to control the exact range of records to process for the file.
That would be a nice way to also perform recoveries for print files. User edits a .json file, dumps the data into a hot folder, the Workflow reads the .json file via a script and that range of records gets reprocessed. Useful for PostScript output. Great idea!
I just realised I had another way to “reduce record range”, however, in around 2019 support said my idea would not work due to a SQL bug in either job preset or output preset. I don’t think it was fixed in 2021.1 but might be in 2023. I will have to check my OL support ticket emails to remember this idea. I will post here after I have revisited it.
(Really wish OL did not close down in RSA as dealing with resellers is a lot slower. Cannot wait to upgrade to 2023.)