I have a text file that can have between 3 and N lines, where
Line 1: BANNER…
data
data
data
data
…
Last line: END OF FILE…
The “data” lines are always the same length.
What is the best way to extract these lines so that they fit into an A4-sized Print Section and that all data appears on the page, regardless of how many pages are generated?
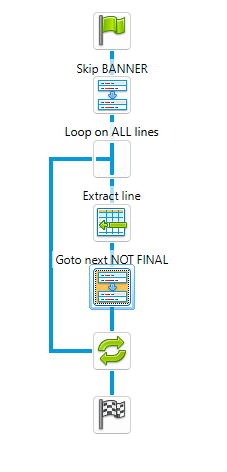
I would create a detail table that contains all the lines, except for the first one and the last one.
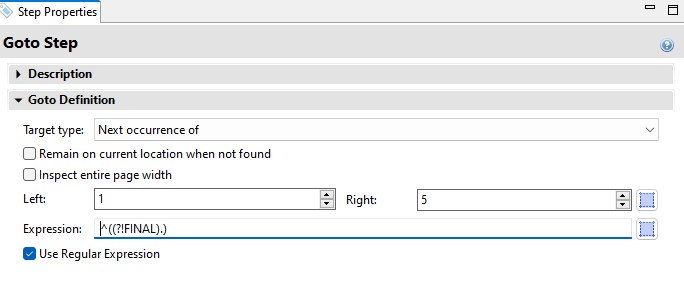
The Goto next NOT FINAL step is the only one that needs explanation: it uses a Regular expression to skip to the next line that does not contain the word “FINAL”:
Good morning, Phil. Thanks for the response, would you mind sharing this DM file so I can understand it better? I haven’t worked with the loop and GO TO steps yet.
A good start to the year to everyone!
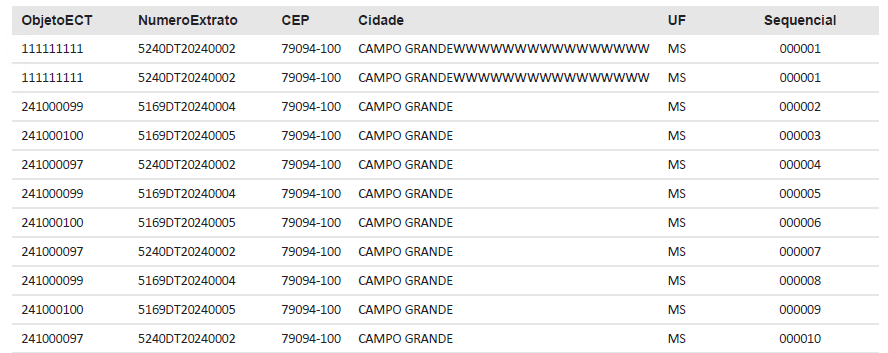
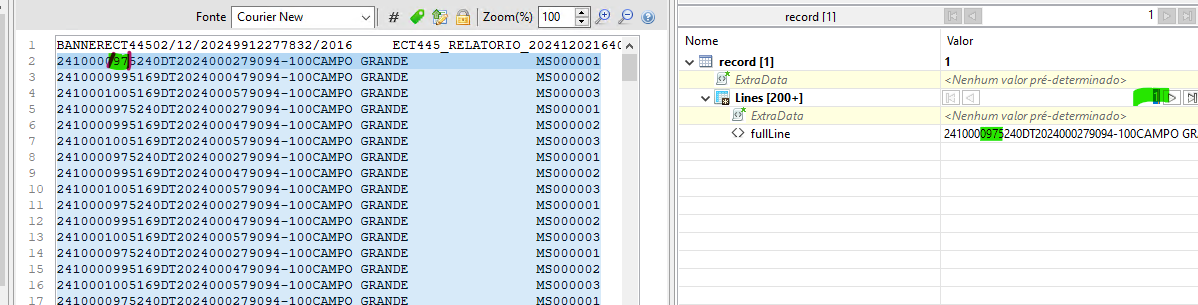
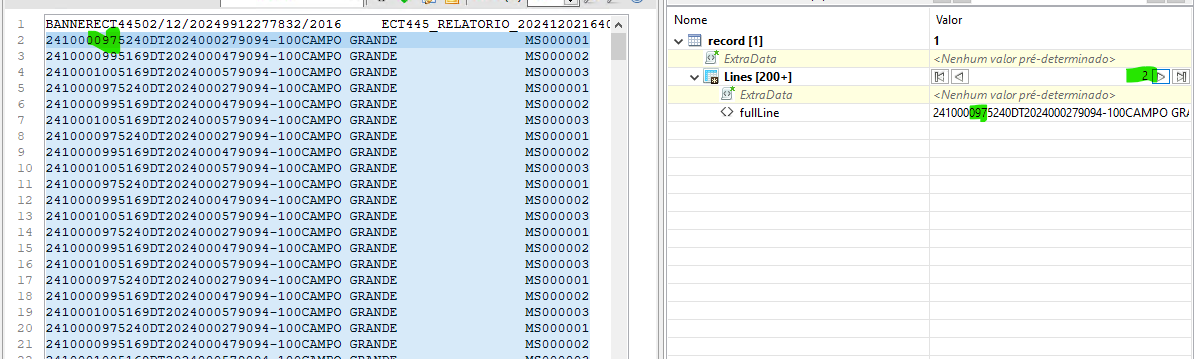
Analyzing the file here, I noticed that when assembling the pivot table, the first line ends up being duplicated, as shown in the image below. I verified in the DM that in fact records 1 and 2 end up looping through the first line of data, in this case line 2 of the file, twice.
How could you prevent this from happening?
Did you make changes to the looping provided by Phil?
I just looked at the DM he provided you and don’t see this duplication.
Can you share your new DM with a anonymized data sameple that reproduce the problem?