Please let me know if the following phenomena are possible.
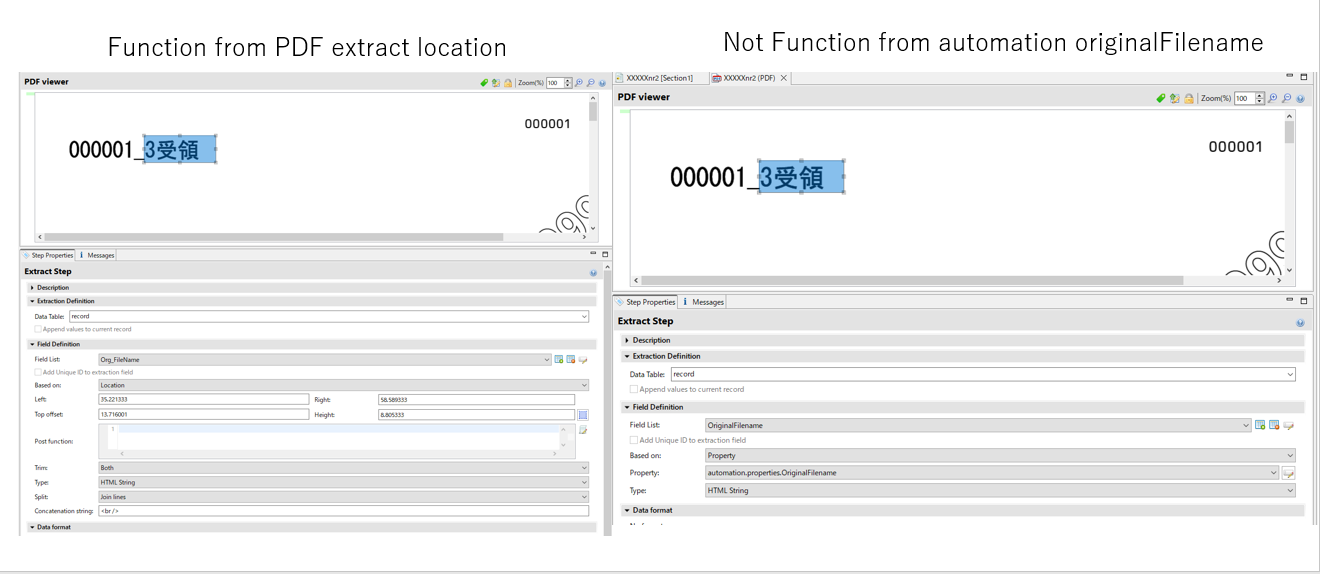
In OLC Automate, automation.properties.Originalfilename does not work.
When there are 3 types of input PDFs and the handling is changed according to the conditions
1_TypeA.pdf
2_TypeB.pdf
3_TypeC.pdf
OLC could handle correctly both the filename and the character extraction in the PDF,
But OLC Automate, the former did not work. The latter is OK.
There are many cases where the decision is based on the file name, so if there is a way to deal with this, I would appreciate it if you could tell me.
The WF I am testing this time is as attached.
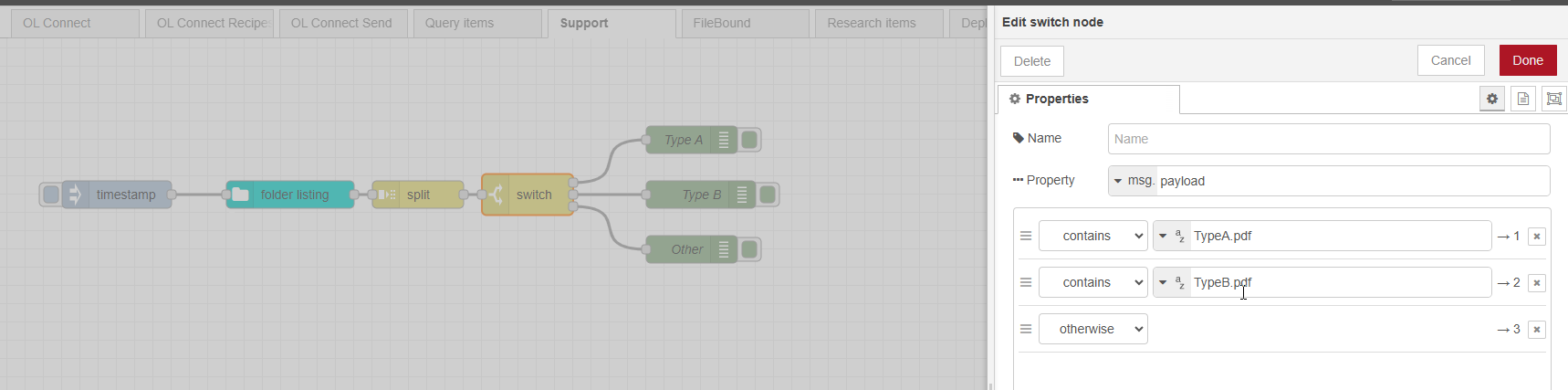
Not sure if I understood the question correctly. But here is several ways to perform a text condition based on a string. In the following example I used the ‘change’ node and set the ‘contains’ option to test the string in msg.payload. You can use this to direct the message to a branch. Not sure if this is what you are looking for.
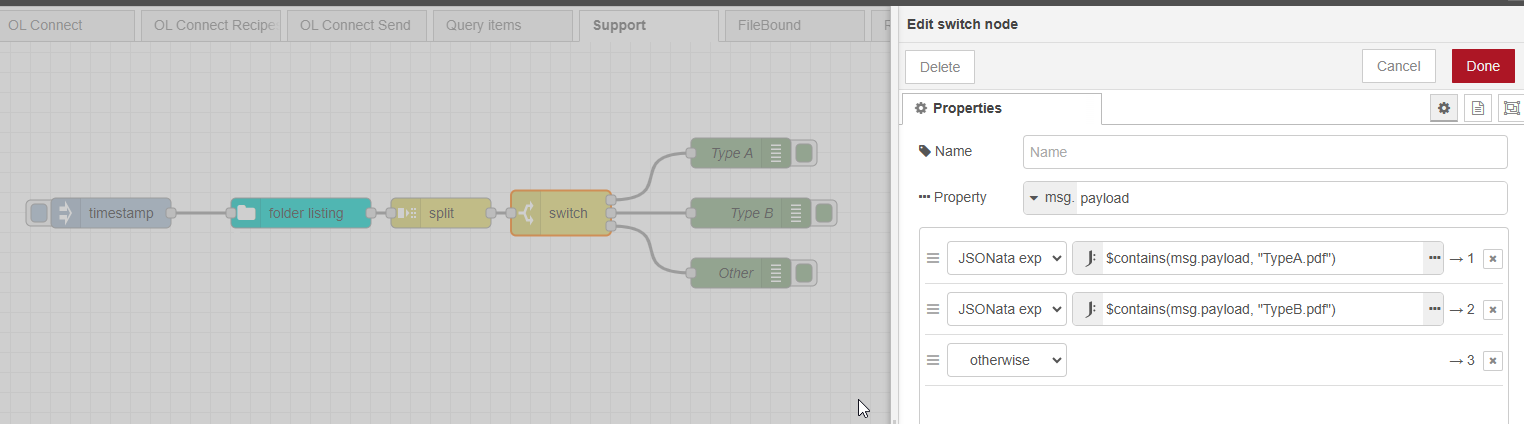
There are additional options like using regex or JSONata expressions but this are prob a bit more technical. You could also handle this in a function node, but this requires JavaScript knowledge.
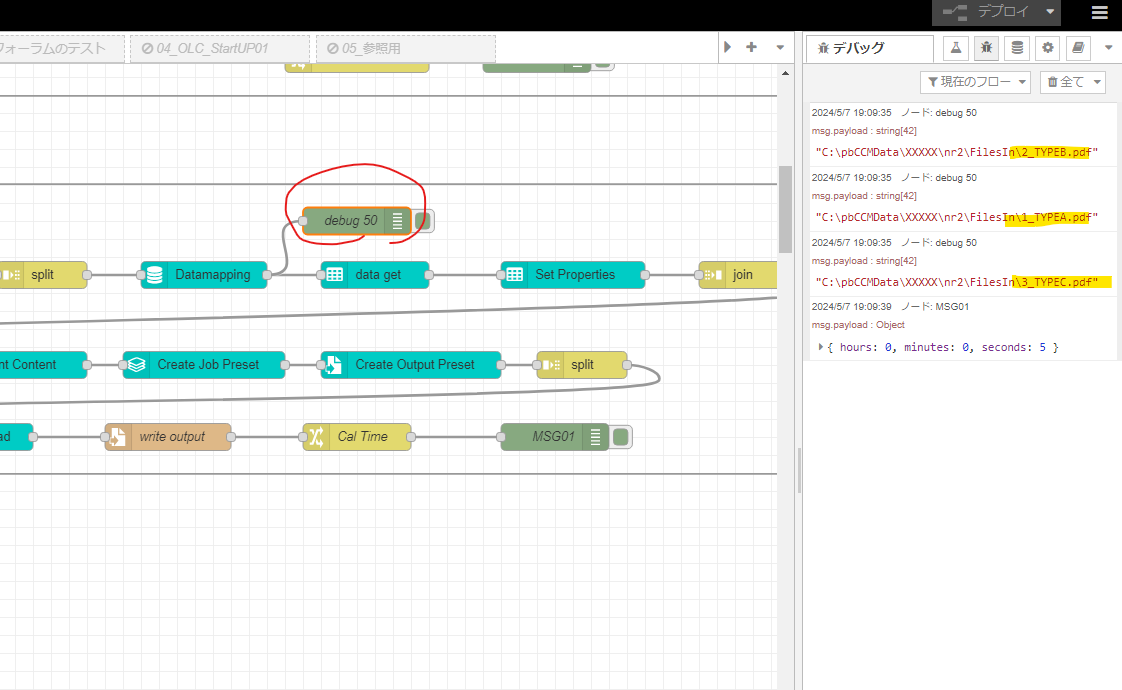
Node-Red seems to be able to recognize the three files, but it appears that the filenames are not recognized on the Datamapper side.
OLC’s WF is able to do this, so I think it may be a problem between Node-Red and Datamapper.
I’ll dive into that, don’t think this parameter is automatically populated today and could require an extra step (something we should fix in an oncoming version).
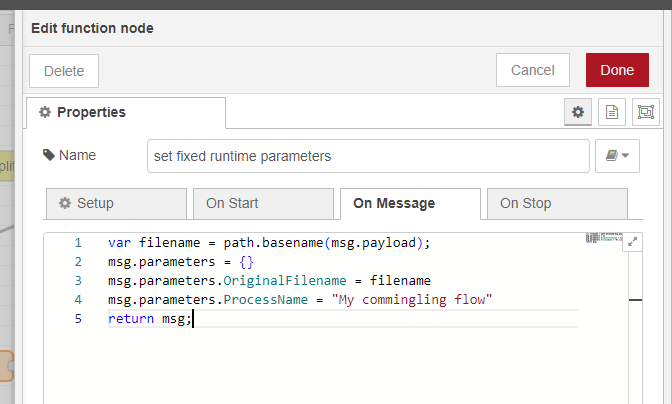
I had to go through a few hoops but this is how I fixed it using a function node. It basically populates msg.parameters with the special “fixed runtime parameters” like OriginalFilename and ProcessName. See the images below.
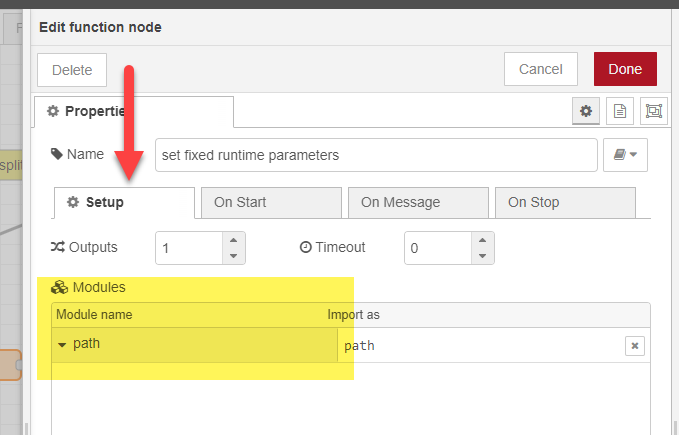
To simplify things I added the ‘path’ module in the ‘Setup’ tab of the function node. This provides a simple method to extract the basename from the full path in msg.payload.
We will add support for these fixed runtime parameters in a future version of the OL Connect nodes so they are provided automatically to the DataMapper engine.
Erik
PS. It is not needed to add these parameters to the Parameters panel in the data mapping configuration.
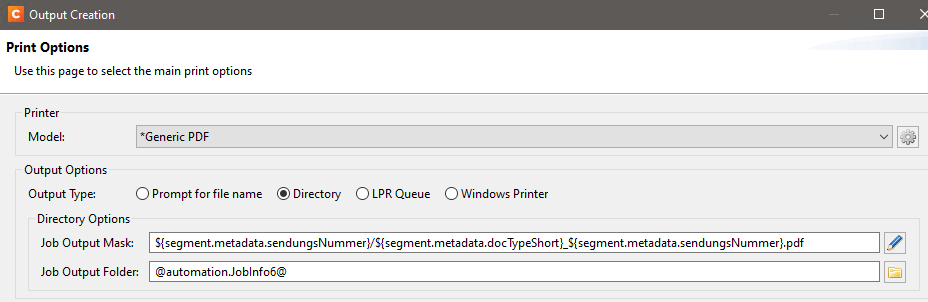
I followed your above advice for OriginalFilename and ProcessName but with JobInfo6. It looks like it does not work properly. In the Connect Server log I get an error (please ignore the error itself) showing the used path:
Thanks for reaching out. Unfortunately, this isn’t currently possible. However, it is on our list of improvements, although we plan to take a slightly different approach.
With the release of OL Connect 2024.2, we’ve updated the underlying REST API to allow specifying the output folder location within the request. When provided, this location will take precedence over what is set in the preset.
We also plan to make the Job Output Folder configurable through the UI in the Properties dialog of the Paginated Output node. This will allow you to set it using, for example, msg.jobOutputFolder , another property, or even construct the path dynamically using a J expression based on variables. As mentioned, the jobOutputFolder will override the output preset settings, making it easier to share your preset across different environments.
For now, the simplest approach is likely to use a common root folder and manage subfolders like you did in the Job Output Mask. Alternatively, you could create a preset for each environment and toggle between them dynamically. Admittedly not the most elegant solution, but we appreciate your patience as we work on improvements.
Another thing: Is there a native method to wait for output to be finished (paginated output with output option “Managed by Output Preset”)?
I have a flow which writes single pdf files in a variable folder with variable file names. After generating these files I have to use them further more. But currently my flow continues without waiting and so the following flow will throw an error.
Could you share more about what the next steps in your automation process involve? Understanding the specific actions you’re taking might help me identify the best solution.
Hi Erik,
I habe to create single pdf files per customer nr and content type (mailing, invoice, etc). So I have to create a job folder with variable name (unique id dynamically created) and within that folder I have to create a customer folder per customer nr (folder name = customer nr) and in that subfolders I store the single pdfs per customer (e.g. mailing.pdf, invoice.pdf). Thats necessary for archiving and a later check.
Thats why I use splitted output via connect in a flow and it works fine. But in the next step I need to use these single pdf files to create a single print file with inserter markings. So I would do a folder listing to create a json input file and within Connect I would set the single pdfs as background pdfs (dynamically clone section to get all section pdfs per record).
I could manage this normally but I dont know how I can set the flow to wait for completing the first Connect output.
Or is there a better way?
Why I would like to handle it that way: I have to execute extremely big xml files per content type to create the content and I dont want to execute it twice (for single files and again for print file). The next problem: There will be a lot of xml files per content type because one there are too many records at all (around 1 million records) and all single parts have to be in one output at the end because I have to split it based on the amount of sheets (for postage).
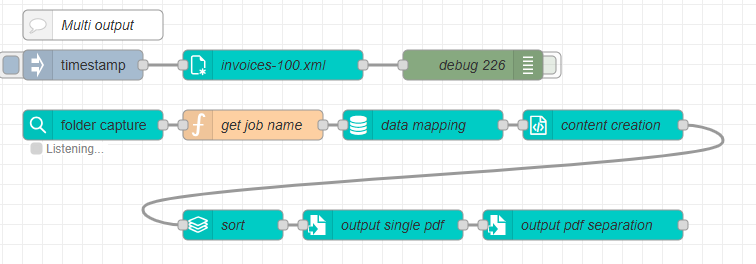
If needed you could run a second job preset on the same content set. I ran a quick test to create a single pdf for the full job and output invoices to customer specific folders. Customers may have one or more invoices.
This way the data and content creation is handled only once.