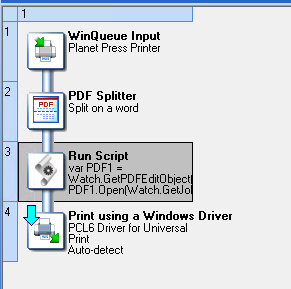
I am attempting to add a blank page in the workflow process using the Alembic Editor. I have the following code i am attempting to run with the run script process:
var PDF1 = Watch.GetPDFEditObject();
PDF1.Open(Watch.GetJobFileName(),false);
var pdfRect = PDF1.Pages(0).Size();
PDF1.Pages().Insert(0, pdfRect);
PDF1.Save();
PDF1.Close();
In my workflow I print to the PP printer, use the pdf splitter to split on a word, and then attempt to try and add a blank page before each of those documents.
Works great except when I have a single page, then I get an error for an Unterminated string when I perform the PDF1.Save(true); in the script. Unfortunately there are several 1 page PDF files in the batch of PDF files
I don’t know if this matters, but the input data files are PDF 1.3.
W3602 : Error 0 on line 16, column 1: AlambicEdit.AlambicEditPDF.1: Error saving PDF to 'C:\ProgramData\Objectif Lune\PlanetPress Workflow 8\PlanetPress Watch\Debug\debugE70F0EE.dat': Unterminated string.
Works fine on my end, regardless of the number of pages. The PDF version number is irrelevant.
I am running this in Workflow 2020.2, but it should work with any version of OL Connect Workflow.
Here’s a sample one-page PDF I used to test it out: 1-page invoice.pdf (200.0 KB) . Try it on your system and see if that works. If it does, then we know it’s something to do with your own 1-page PDFs, which will help us narrow down the cause of the issue.
There’s definitely something peculiar about that PDF you sent. Using Acrobat, I can’t even view the Properties for the file (CTRL-D). It also looks like that one-pager was actually extracted from a larger 21-page file, I suspect this may have something to do with the issue (as if some resources weren’t exported along with that one page).
I unfortunately don’t have the tools to explore the matter any further, I will ask our dev team to take a look at it. I’ll keep you posted.
We don’t have control over the PDF creation, we just consume the files.
It will be good to know why. I have three different scripts and all three fail on the one pagers.
By the way, I suggest you use the same code for all PDFs, not just those to which you have to add a blank page, as the script has the effect of creating a normalized PDF. This will prevent issues down the road if the PDFs ever need any additional processing.
Our R&D team has taken a look at the sample file you provided. As we suspected, the file is broken. Acrobat Pro, when asked to report PDF syntax issues, returns the following message: An error occurred while parsing a contents stream. Unable to analyze the PDF file.
When attempting to save the document, Acrobat Pro encounters an error. When trying to browse the internal structure of the document, Acrobat Pro returns an unhandled exception message, which essentially means it can’t make heads or tails of the file.
So my initial hunch seems to be correct: whatever process extracted that one-page file from a larger one seems to have done a really poor job of it. There is nothing we can do to fix the file after the fact, so my suggestion stands: use the last script I posted to create a brand new PDF before you attempt to make any changes to it. Fortunately, for one-pagers, this won’t introduce any noticeable delays into the entire workflow.
Thanks for the quick answer.
I tried putting together some code to accommodate that command, but I am very unfamiliar with Alembic code
I have no idea what I am doing, as far as this code goes.