Coming from older versions of Connect I noticed a new endpoint described in the link below.
Where does a document fit in the pipeline of OlConnect?
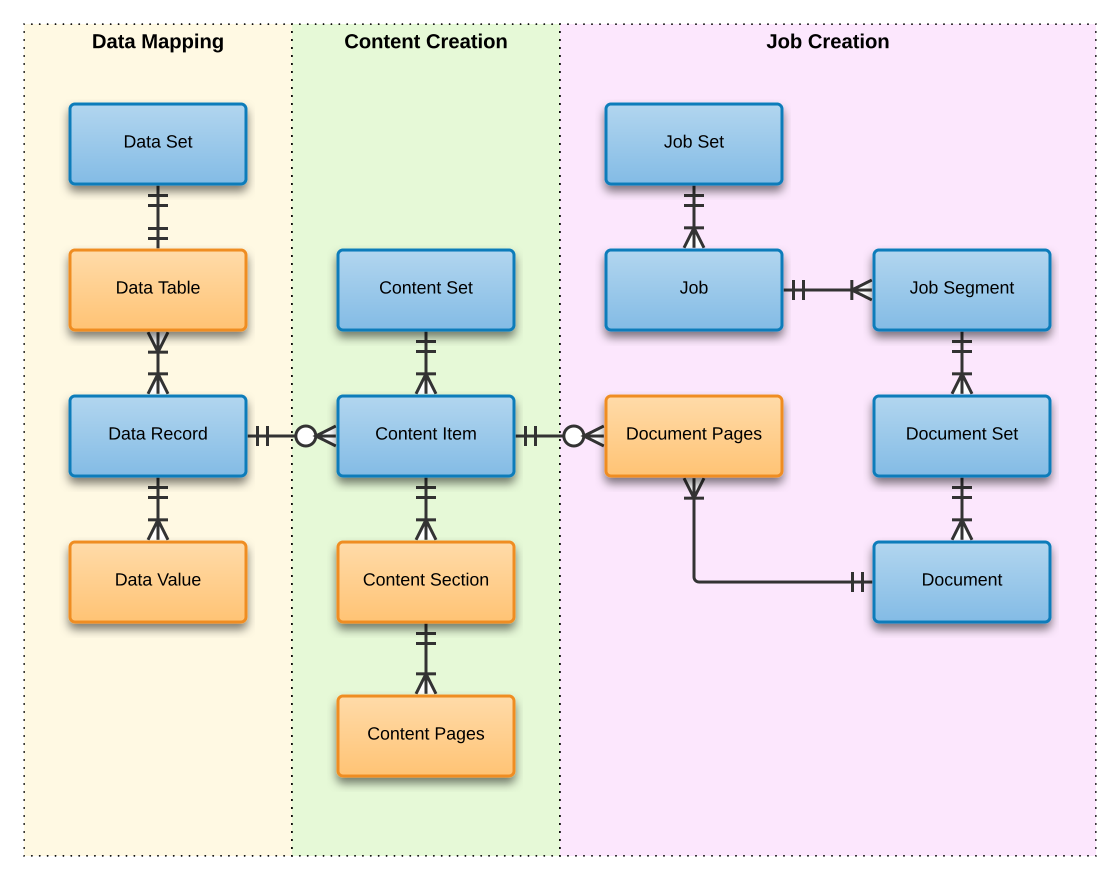
Seems like a Document is the result of the merge of a record with a template but that’s what a Content Item is according to the rest of the APIs and the diagrams shown. I’m a bit confused and I was hoping for some clarifications.
The content item is the raw form of your document, that is to say it is only the result of the data being merged onto a template. The document is the final version, which may include additional content added through the output preset, for instance.
Thanks for the clarification, if the document entity is the final representation of a content item, shouldn’t it be available after the output creation execution where additional content may be applied?
My understanding of your understanding (?!?) is that you are mostly correct.
A document consists in an assembly of one or more content items, each of which is produced by merging a data record with a template. Each document is intended for a distinct recipient; in other words, there is a 1:1 relationship between a document and a recipient.
The role of the Job Creation operation is to produce a job set, i.e. a hierarchy of containers which help producing a vast number of documents which need to be logically grouped for production and handling purposes (e.g. postal sorting).
The role of the Output Creation operation on the other hand is to convert the so-far virtual concept of the job set into tangible assets such as PDF files or print jobs. It also allows to adapt to production methods, e.g. applying barcodes to drive finishing hardware such as inserters.
Therefore, the term document may mean either, in its formal definition, a collection of content items within a job set, or more familiarily, the final asset that the recipient receives, depending on the context.
As for the Job Statistics, it appears that the it may have missed one key point that a document may consists in multiple content items, a process which is commonly called comingling. The documentation is also inaccurate, stating that some properties are strings when they really are numbers. This would need to be reviewed.
If that’s the case and strictly referring to the APIs entities when performing commingling (either done through grouping in the Job Preset or manually manipulating the Job Set with the other endpoints) different content items are rearranged to be part of the same Document, so the JSON structur of a Document should have an array of tuples of content items and record items on which the Document is built.
However, continuing on this line of thought, how would properties be handled? If multiple documents are commingled together, each with its properties, the JSON of the docs shows only one list of properties, so some are lost, or overwritten? In which order of precedence?
I would expect the JSON to be:
{
/.../
"documents": [
{
"documentId": 13217931, <-- somewher here the keys should be arranged
"contentItemId": 1179516, to have contentItemId and dataRecordId in pairs in an array?
"dataRecordId": 2553516,
"properties": { <-- how would properties be managed? a mere merge?
"FirstName": "Norris",
"LastName": "Schiffman",
"Phone1": ""
},
"counts": {
"sheets": 1,
"pages": 1
},
"media": {
"0": 1
}
}
]
}
Anyway, the Job Statistics Endpoint documentation should indeed be revised or maybe a technical blog post could expand on how these pieces fit and interact together with a practical example of API driven workflow.
Properties are applied directly to an entity, they are not inherited. A job set document therefore has an empty property list when it is created, regardless of the content sets or data records that compose it. This solves the potential conflict you refer to. It also handles the case where e.g. each content item may have different, unrelated properties, causing the structure size to explode.
The Job Statistics structure addresses a specific use case, for when certain characteristics of a job are required for production processing. It is not meant to be an all-encompassing structure that contains every single piece of information.
If one wishes to retrieve properties from e.g. content items, there are endpoints in the REST API that allow to do so.
For example, data records are referenced by ID, they are not inlined within the structure either. From the data record ID, it is possible to retrieve the master record, detail tables, properties, etc., but with additional REST calls, if so desired.